メタ分析とは、過去に報告されたいくつもの研究を統合して、研究全体の推定値を得る解析方法です。
まず、メタ分析に必要な効果量や標準誤差を指定してStataにメタデータを宣言します。
meta set meta esizeなどのmetaコマンドを使用します。
必要があれば、メタ分析の過程でmeta updateコマンドを使い、初期設定を更新することができます。
詳細はmata dataをご参照ください。
先生の期待が生徒のIQに及ぼす影響のデータを入手し、生徒のIQについて考察します。
下記のコマンドを入力してデータをダウンロードし、内容を確認します。
.use https://www.stata-press.com/data/r16/pupiliq
. describe studylbl stdmdiff se week1
以下の表が表示されます。
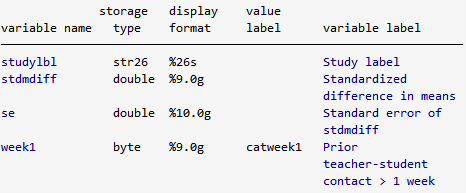
データセットには、効果量stdmdiffと、その標準誤差seが含まれています。
これらをmeta setで指定し、さらに表示オプションのstudylabelにstudylbl、eslabelにStd. Mean Diff.を入力します。
.meta set stdmdiff se, studylabel(studylbl) eslabel(Std. Mean Diff.)

このメタ分析には、K=19の研究(研究ID、効果量、標準誤差)が含まれています。
「Method: REML」は変量モデル(randam-effects model)が適用されていることを意味します。
適用するモデルは、metaコマンドのオプションで変更することができます。
metaコマンドは、_meta_cil(効果量の信頼区間の最小値)と_meta_ciu(効果量の信頼区間の最大値)などのシステム変数を自動生成します。
meta summarizeコマンドを使って例1の研究を統合し、全体の効果量を推定しましょう
.meta summarize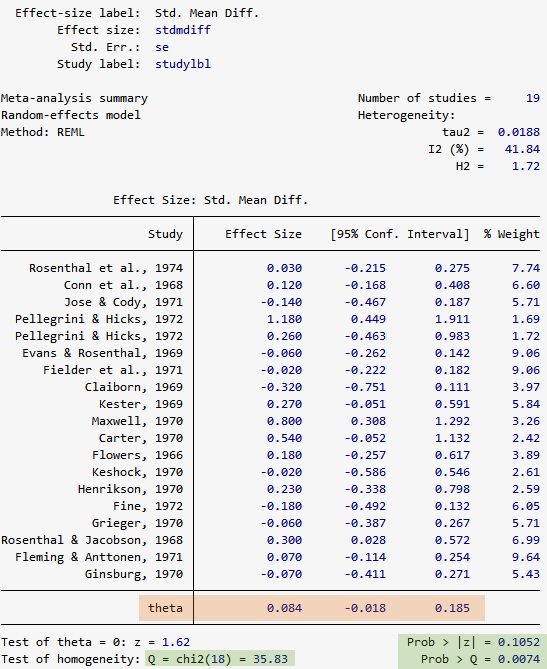
全体の効果量θ(theta)は、各研究の効果量の加重平均です。
例1での推定値0.084は、95%信頼区間 [-0.018, 0.185] の範囲内です。
有意性検定H_0:θ=0はP値が0.1052なので、全体の効果量と個別の研究の効果量の有意差はほぼ0です。
θは、H_0:θ_1=θ_2⋯θ_19=0が帰無仮説となります。
コクランのQ統計量は35.83で、P値が0.0074です。
これは、「統合した効果量に異質性はない」という帰無仮説を棄却します。
異質性はI2でも確認できます。
異質性の尺度I^2=41.84なので、効果量の推定の異質性の42%が研究の差異によるものとなります。
研究間の異質性は、最終的なメタ分析を行う前に処理する必要があります。
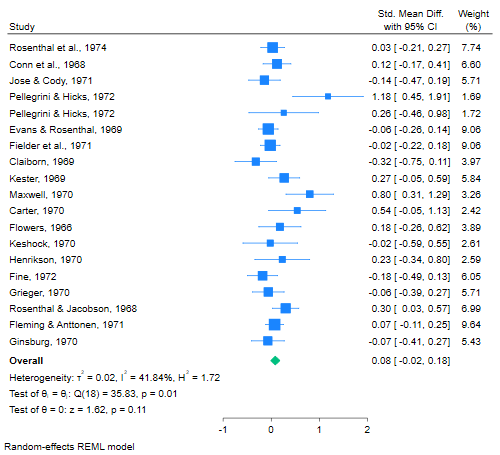
メタ分析の結果は、一般的にフォレストプロットで図示します。以下のコマンドで、上記結果からフォレストプロットを作成します。
フォレストプロットは、個々の研究の効果量を容易に比較でき、統合結果の効果量とどのくらいの類似性があるかを見ることができます。
. meta forestplot
例2の結果が図示されます。青の■のプロットは効果量で、その大きさはWeightに応じます。
横線で95%信頼区間を示しています。全体の効果量は緑の◆です。
◆の横幅が95%信頼区間を示しています。
この例では、いくつかの研究の効果量が全体の効果量と、大きく異なっていて、95%信頼区間が重なっていない研究もあります。
したがって、個々の研究に異質性があるといえます。
ここまでの例題では、先生の期待が生徒のIQに及ぼす影響について分析してきました。
Raudenbush(1984)は、ピグマリオン効果(先生が過剰にコミュニケーションを取るとマイナスの効果が生じる)を疑いました。
引き続き、これまでの例題を扱います。
このデータには、week1という変数があり、先生と生徒の接触量を表しています。
1週間より長い時間コミュニケーションを取るグループを高接触グループ、1週間以下のグループを低接触グループとします。
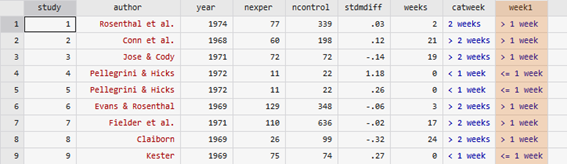
各研究を、この2つのグループに分けてメタ分析を行います。
Raudenbushの仮説では、低接触グループで効果が大きくなり、高接触グループで効果が小さくなるはずです。
下記のコマンドを実行して、week1でグループ分けしたメタ分析を行います。
. meta summarize, subgroup(week1)
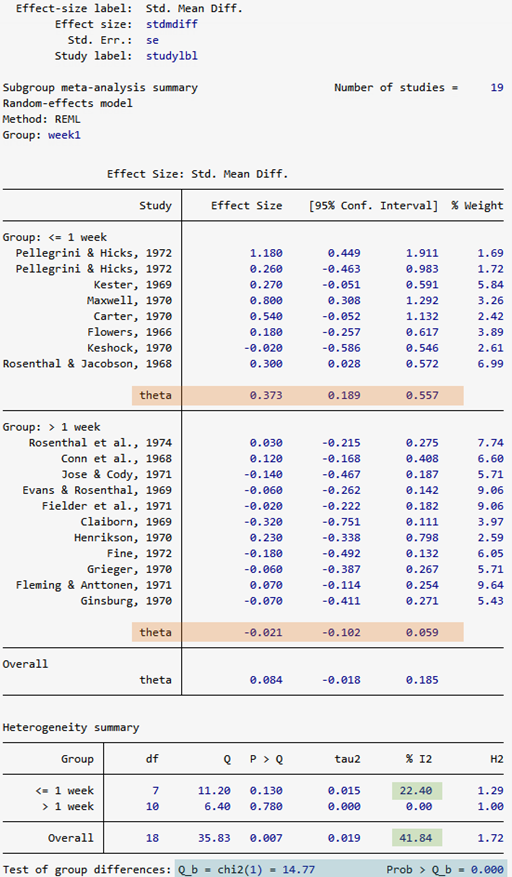
グループを分けると、低接触グループでは効果量が0.373(95%信頼区間[0.189, 0.557])と推定され、統計的に有為な結果になります。
一方、高接触グループでは効果量は-0.021(95%信頼区間[-0.102, 0.059])で、5%有意水準で0と変わらない結果になります。
先生のコミュニケーションの有無が、生徒の成績に影響を与えているといえます。
グループ内での各研究の異質性は、グループ分けする前に比べて小さくなっています。
全体の研究ではI^2=41.84ですが、低接触グループの中ではI^2=22.40です。
高接触グループでは、異質性がありません。
コクランのQは、グループ間の差を検定しています。Q=14.77、P値=0.000なので、高接触グループと低接触グループの効果量に差があることを示しています。
フォレストプロットでも効果量を確認します。
. meta forestplot, subgroup(week1)

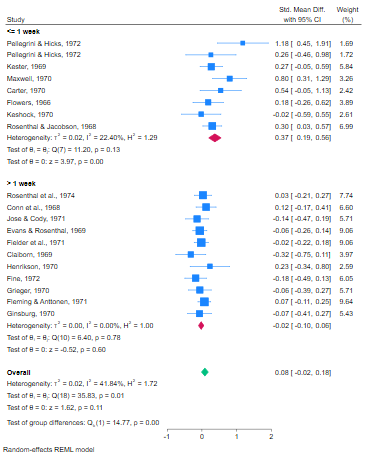
コミュニケーション量によってデータを分けることで、高接触グループでは特に効果量の異質性が小さくなり、異質性を説明することができました。
ただし、データを分けることによってサンプル数が少なくなってしまうため、不十分な分析になってしまう可能性があることに注意してください
心筋梗塞を発症した患者に対するストレプトキナーゼ(血栓溶解薬)の効果についてのデータを使用します
. use https://www.stata-press.com/data/r16/strepto, clear
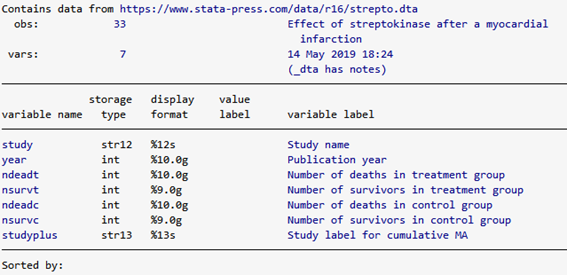
. describe
まず、metaコマンドを使用するための準備をします。
このデータセットには、各研究にndeadt(治療群の死亡数)、nsurvt(治療群の生存数)、ndeadc(コントロール群の死亡数)、nsurvc(コントロール群の生存数)のデータがあります。
このデータは、下記のように2行2列で表すことができます。
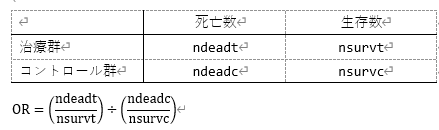
Lau et al.(1992)は、効果量の大きさとしてオッズ比が使用できるのではなかと考えました。
メタ分析では、オッズ比を対数として扱います。
Stataでは、meta esizeコマンドで対数オッズ比を計算してメタ分析を実行することができます。
meta esizeコマンドにオッズ比を計算する4つの変数を指定し、例1と同様にstudylabelオプションを入力します。
. meta esize ndeadt nsurvt ndeadc nsurvc, studylabel(studyplus) common

33の研究が分析に使用されていて、対数オッズ比を効果量としています。
esize()オプションを使用すると、対数リスク比、リスク差、Petoの対数オッズ比などを効果量として指定することができます。
meta updateコマンドを使用すると、効果量の種類を簡単に変更することができます。
Lau et al.(1992)は、長期間蓄積された様々な研究データを使用して、ストレプトキナーゼの効果についての累積メタ分析を行いました。
この研究で使われた方法を再現してみます。
cumulative(year)オプションを使用してフォレストプロットを作成します。
このオプションを使用すると、対数オッズ比ではなくオッズ比でグラフを作成することができます。
Lau et al.(1992)のグラフと同じようなグラフにするために、crop(0.5 .)オプションを指定します。
このオプションは信頼区間の下限をトリミングし、0.5以下のオッズ比を対数にします。
. meta forestplot, cumulative(year) or crop(0.5 .)

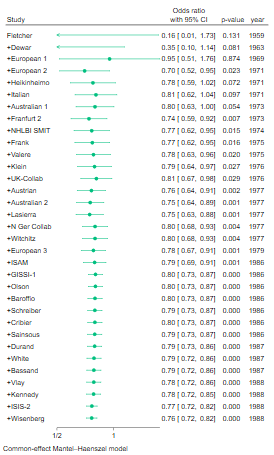
このフォレストプロットは、1つめの研究、1つめの研究と2つめの研究、1~3つめの研究……と、累積した推定値と信頼区間をプロットします。
個々の研究の値はプロットされません。
Studyの+の記号は、その研究が分析に加えられたことを意味します。
全体の研究の効果量を検定するP値も表示されます。
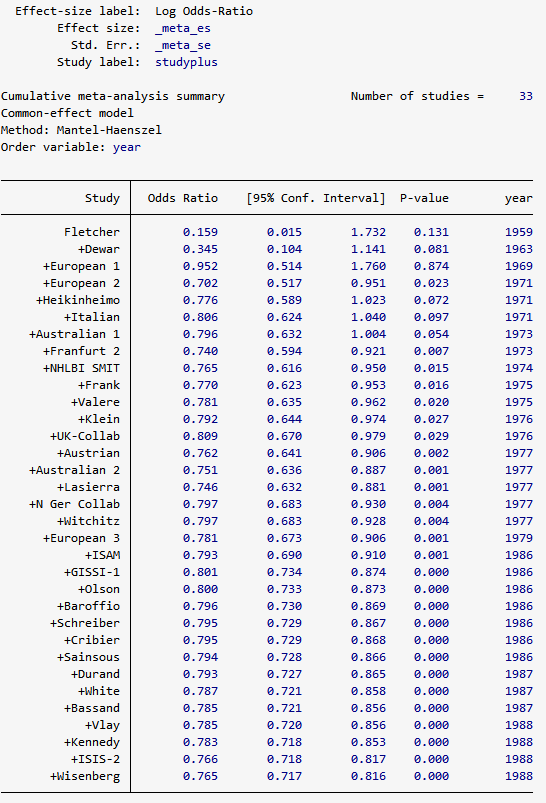
例えば、4つ目の+European 2はオッズ比の推定が0.7、95%信頼区間が[0.52, 0.95]、P値が0.023です。
したがって、上4つの研究を統合すると、ストレプトキナーゼを投与された群はプラセボ群に比べて、23%死亡のオッズ比が低いことがわかります。
meta summarizeコマンドを使うと、この結果を表形式で出力することもできます。
. meta summarize, cumulative(year) or
サブグループメタ分析では、効果量が大きく異なる場合に、研究をグループに分けて異質性を説明しました。
薬の投与量のように、2つのグループを分ける変数に連続性がある場合は、メタ回帰を行います。
結核に対するBCGワクチンの効果についてのデータセットを入手します。
. use https://www.stata-press.com/data/r16/bcg, clear
.describe studylbl npost nnegt nposc nnegc latitude
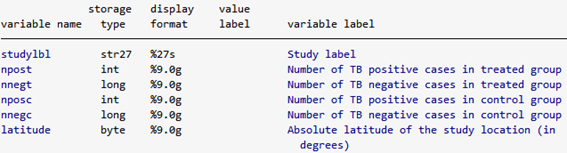
結核陽性の人数(BCGワクチン接種群)、結核陰性の人数(BCGワクチン接種群)、結核陽性の人数(コントロール群)、結核陰性の人数(コントロール群)が入力されています。
meta esizeコマンドを使います。
この例では、リスク比が効果量として使われています
オッズ比と同様に、メタ分析では対数リスク比を計算します。
デフォルト設定ではオッズ比が計算されるので、esize(lnrratio)オプションを使用します。
. meta esize npost nnegt nposc nnegc , esize(lnrratio) studylabel(studylbl)

13の研究データがあり、デフォルト設定のランダムエフェクト推定モデルが適用されています。
Berkery(1995)は、環境バクテリアの存在がBCGの効果を妨げていると推測しました。
そして、環境バクテリアの棲息は緯度に依存するとしました。
そこで、緯度を使用してメタ回帰を行い、Berkeryの説を検証します。
まず、緯度の平均を0として、平均から何度離れているかを表す変数latitude_cを作成します。
平均は33.46度でした。アメリカのアトランタや、レバノンのベイルートがこの緯度に該当します。
. summarize latitude, meanonly
. generate double latitude_c = latitude - r(mean)
. label variable latitude_c "Mean-centered latitude"
変数の設定を行ったら、latitude_cにメタ回帰します。
. meta regress latitude_c
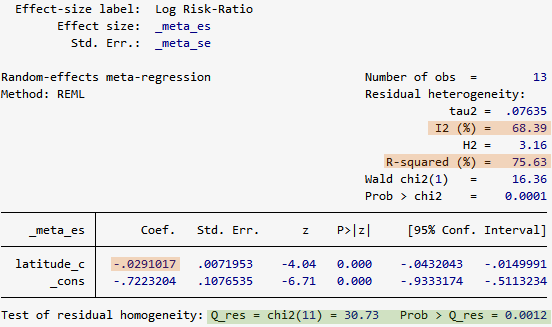
latitude_cの回帰係数は-0.0291で、緯度が1度増えるごとに対数リスク比が0.0291単位小さくなることを示しています。
つまり、ワクチンは寒冷地ほど効果があるといえます。
研究間の共変量による分散は、R^2で評価することができます。
研究間の異質性の75.63%は、共変量latitude_cで説明できます。
I^2の値から、残りの分散の約68%が異質性によるもので、他の共変量で説明されるものであることが分かります。
残りの32%はサンプルの異質性によるものです。
Q_resは30.73で、そのP値は0.0012なので、異質性がないという帰無仮説は却下されます。
これは、残差の異質性があることを示唆するI^2の値と矛盾しません。
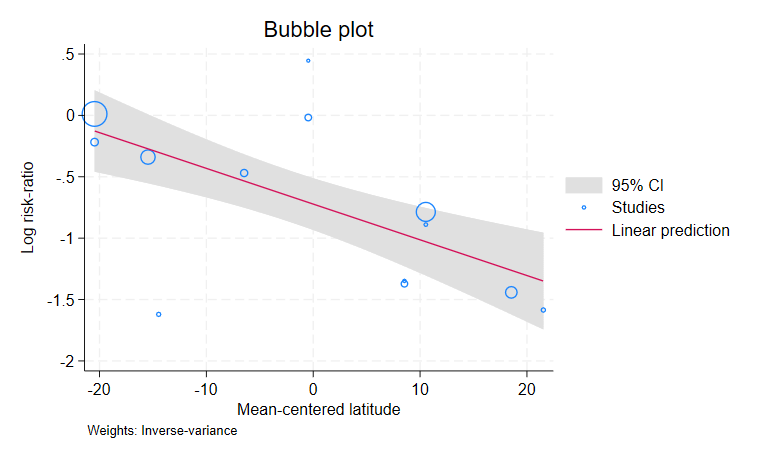
メタ回帰に連続する共変量がある場合、効果量と共変量の関係をバブルプロットで調べることができます。
下記のコマンドを実行し、対数リスク比と緯度の平均からの距離(latitude_c)の関係をバブルプロットにします。
. estat bubbleplot
バブルプロットは、効果量と共変量の値を記した散布図です。
円は各研究を表し、効果量の有為性が高いほど大きい円になります。
フィット関数も表示されます。
対数リスク比は緯度が高くなる程小さくなるため、高緯度地域ほどBCGワクチンの効果が高いといえます。
ただし、いくつかの研究は相関から値が外れているため、検証が必要です。
ファンネルプロット(Light and Pillemer 1984)は、各研究の精度(標準誤差など)に対して、研究固有の効果量をプロットします。
出版バイアスのような、研究が小規模であることが原因で起こるバイアスを調べます。
小規模研究によるバイアスがないと、プロットは左右対称の逆漏斗型になります。
良い結果が出なかった小規模な研究がデータから排除されていると出版バイアスが生じ、ファンネルプロットが非対称になります。
また、研究の間に異質性がある場合も同様です。
非ステロイド性抗炎症薬(NSAIDS)の効果についてのデータセットを入手し、ファンネルプロットを作成します。
. use https://www.stata-press.com/data/r16/nsaids, clear
. describe
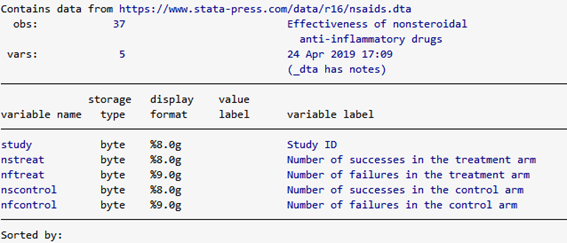
痛みを緩和する治療効果があった数(NSAIDS投与群)、治療効果がなかった数(NSAIDS投与群)、治療効果があった数(コントロール群)、治療効果がなかった数(コントロール群)のデータが含まれています。
まず、meta esizeコマンドでデータの形式を宣言します。
デフォルト設定のオッズ比を使用します。
4つの変数を指定する代わりに、省略形式で指定できます。
meta esizeコマンドに指定する順番と同じ順番で変数リストが並んでいる場合のみ、この省略形式を使うことができます。
. meta esize nstreat-nfcontrol
37の研究データが含まれています。
また、デフォルト設定のランダムエフェクト推定モデルが適用されています。
meta funnelplotコマンドで、ファンネルプロットを作成します
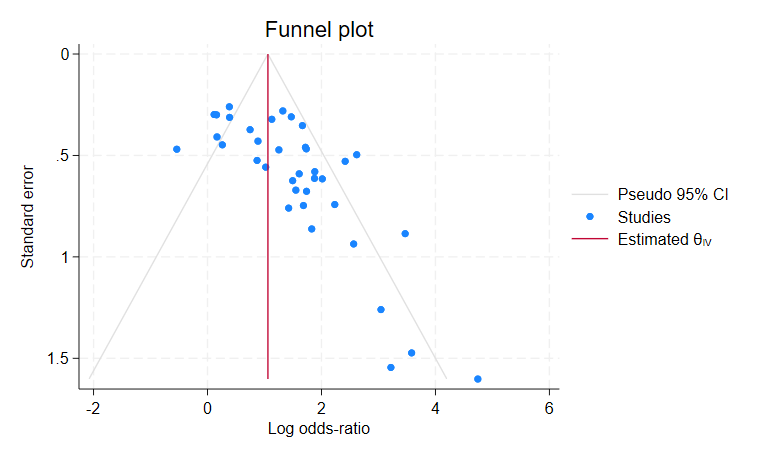
ファンネルプロットでは、標準誤差の小さな研究がグラフの上方に、標準誤差の大きな研究が下方にプロットされます。
中央の赤い線は、全体の研究から推定された影響の大きさ(この例の場合は対数オッズ比)です。
標準誤差の小さな研究は赤い線の付近で異質性が見られ、標準誤差が大きくなるにつれて赤い線から遠いプロットも生じると考えられます。
この例では、左下にプロットがありません。
標準誤差が大きく、対数オッズ比が0に近い研究が報告されていないと推測されます。
Stata is a registered trademark of StataCorp LLC, College Station, TX, USA, and the Stata logo is used with the permission of StataCorp.

ISO27001(ISMS)認証
情報セキュリティ・マネジメントシステム

© 2024 Lightstone Corp. All Rights Reserved
