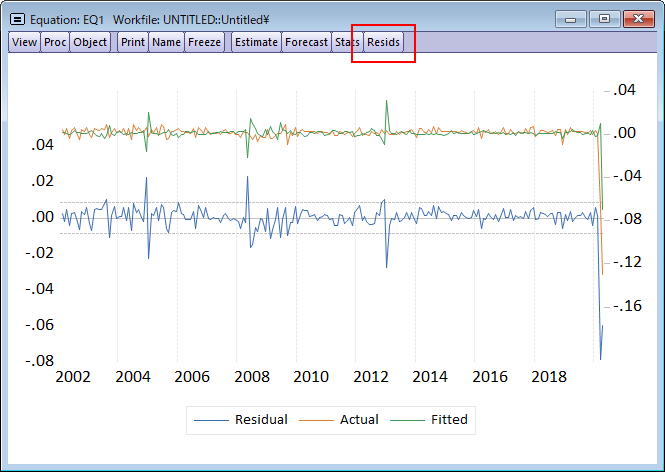
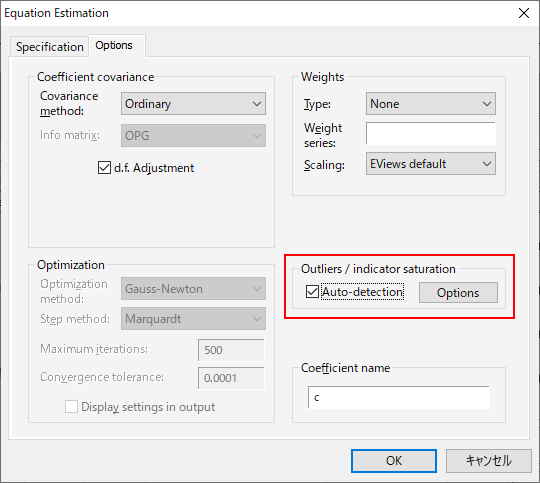
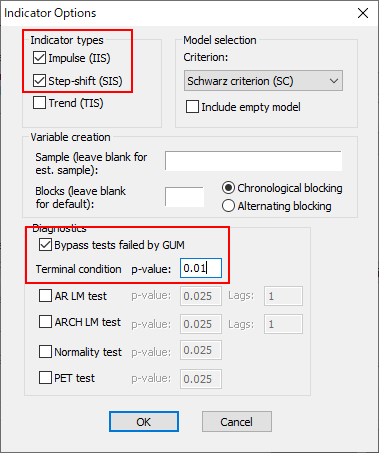
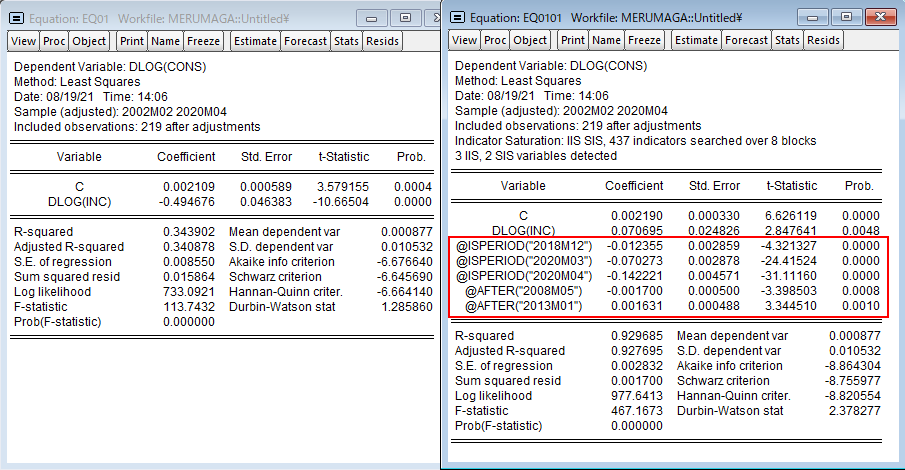
時系列データ分析における問題の1つが、一時的な外れ値と根本的な構造変化の存在です。EViews 12では、インジケータサチュレーションとautomated General-to-Specific (GETS)を利用した外れ値と構造変化の検出機能が追加され、これらを利用してをデータの変化を検出する新機能が登場しました。このページでは、時系列データにおける外れ値と構造変化の自動検出機能をご紹介します。
このページは、開発元のブログ:EViews econometric analysis insight blogを元に作成しています。
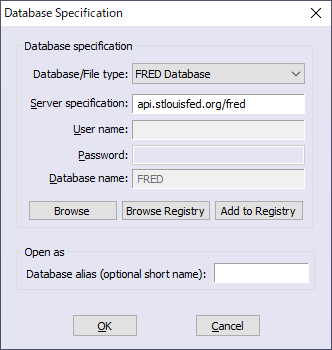
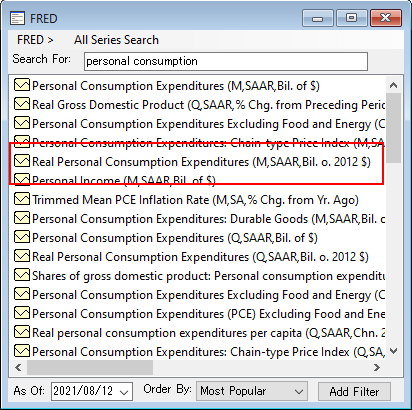
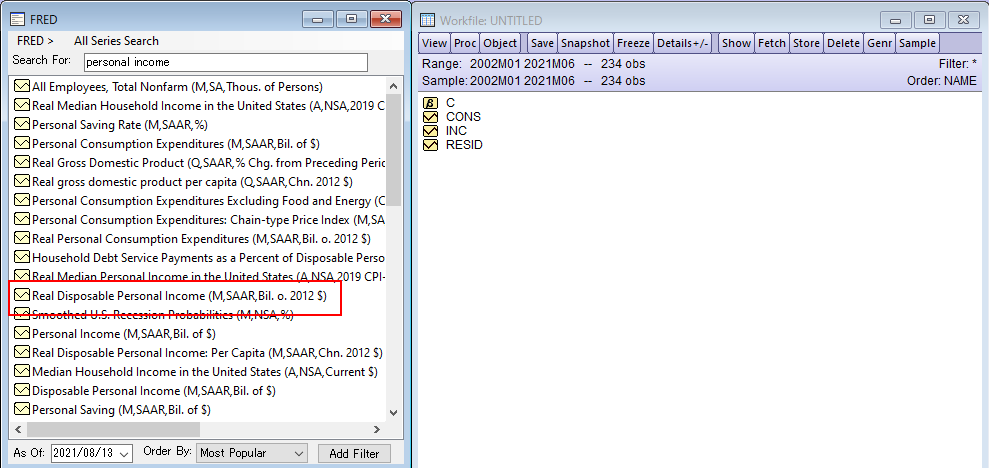
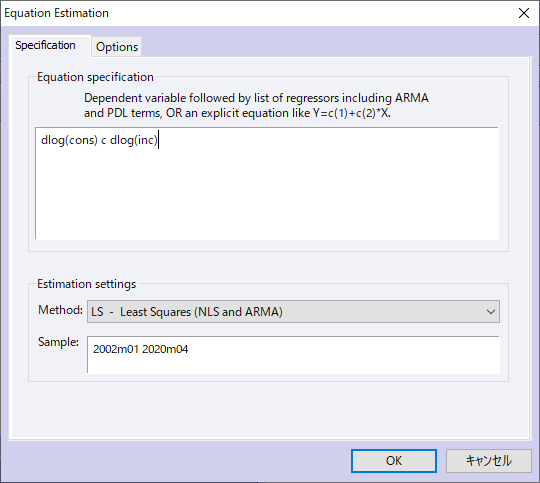
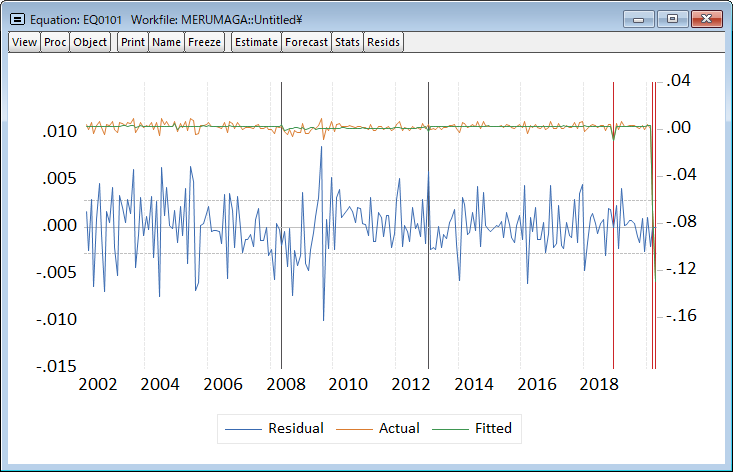
![]() FREDのデータを利用した例
FREDのデータを利用した例

ISO27001(ISMS)認証
情報セキュリティ・マネジメントシステム

© 2026 Lightstone Corp. All Rights Reserved
