Lasso-OLSのハイブリッド、post-Lasso OLS、条件を緩和したLasso(特定の条件下)、またはpost-estimation OLSとしても知られるLASSO変数選択では、変数選択手法としてLASSOを使用し、その後に通常の最小二乗を使用します。
このページでは、開発元ブログ記事を元に、EViewsで行う、LASSOによる変数選択モデルを通常の最小二乗法を比較しながら解説します。
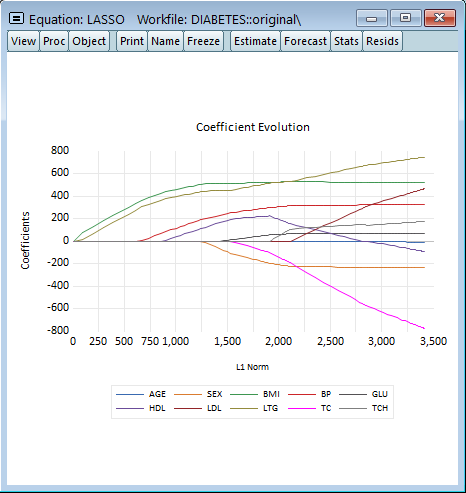
![]() L1罰則項と係数の変化
L1罰則項と係数の変化
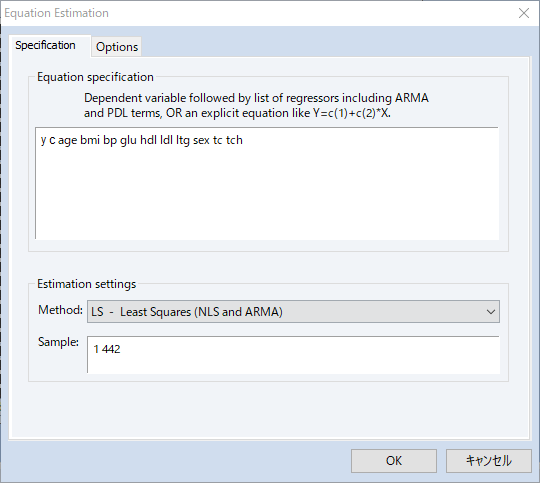
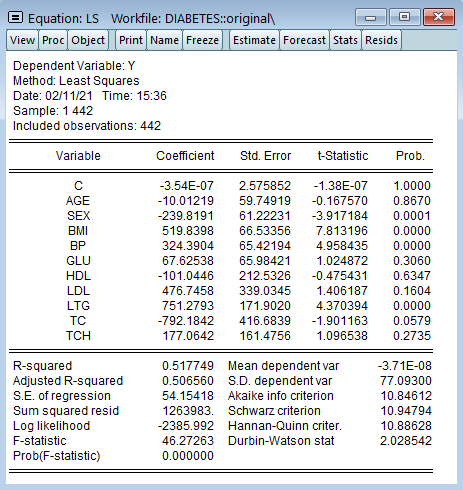
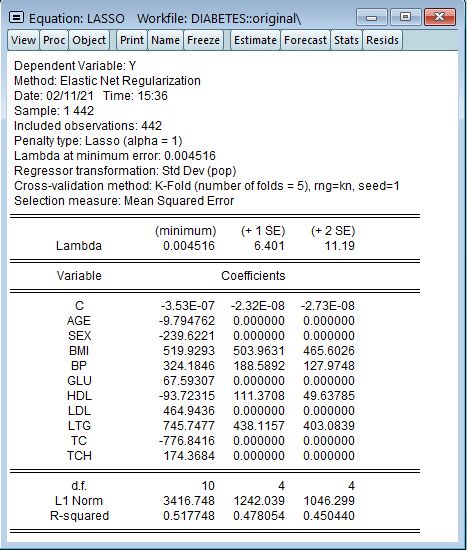
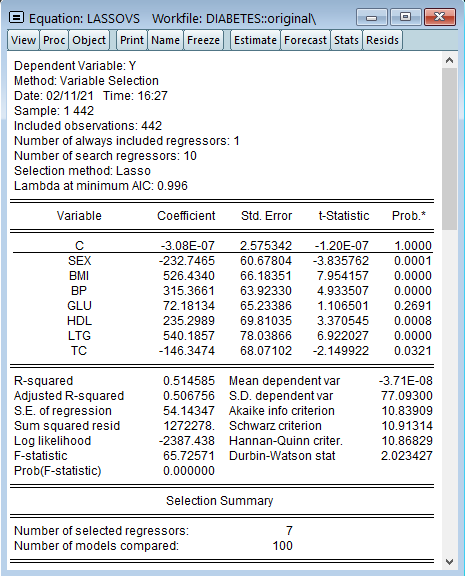
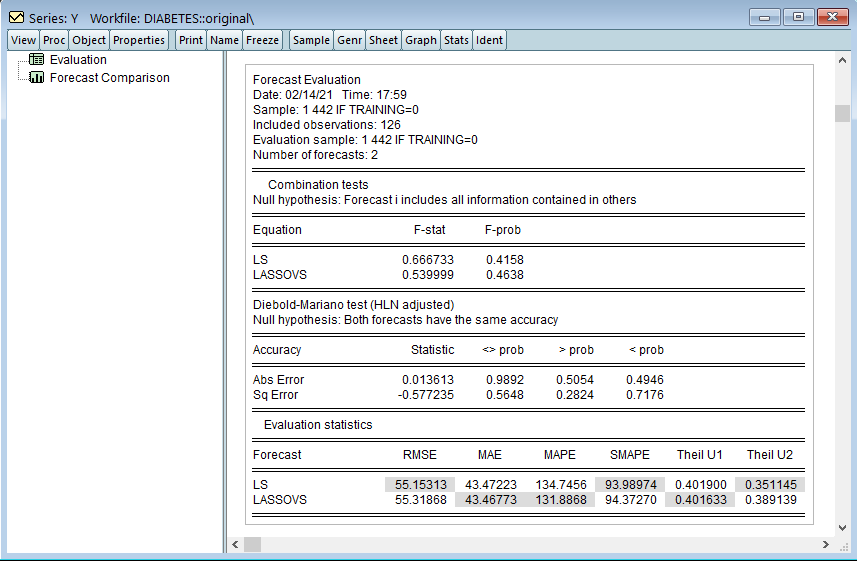
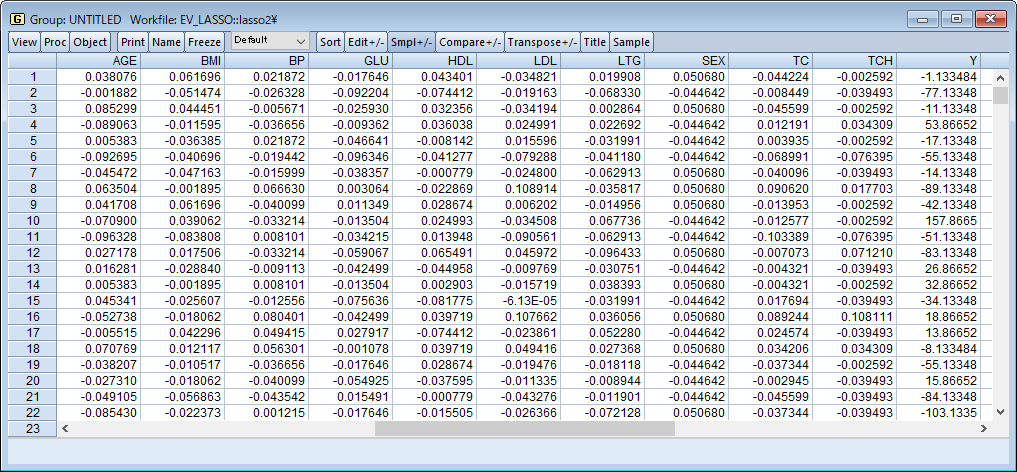
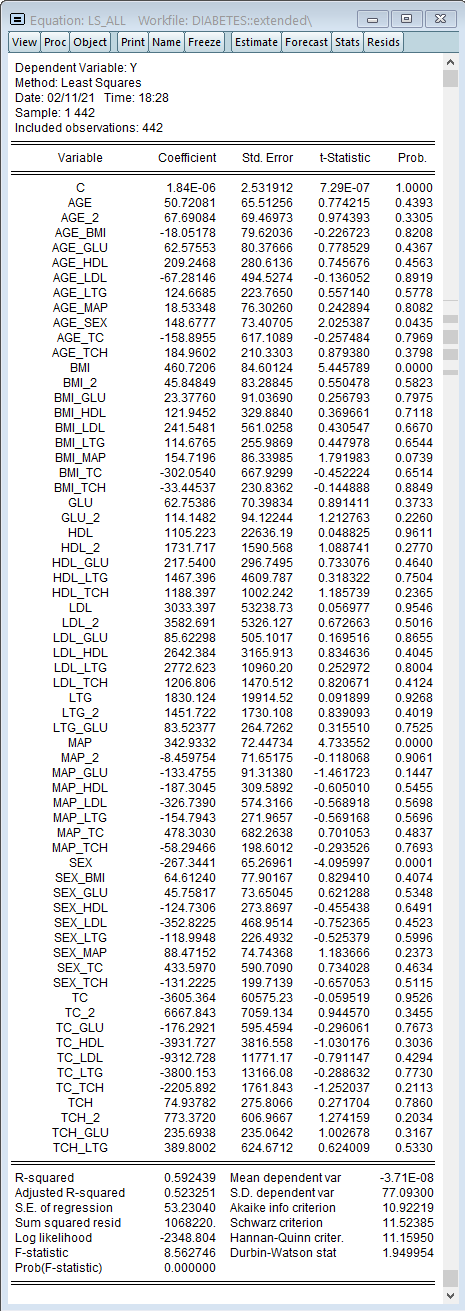
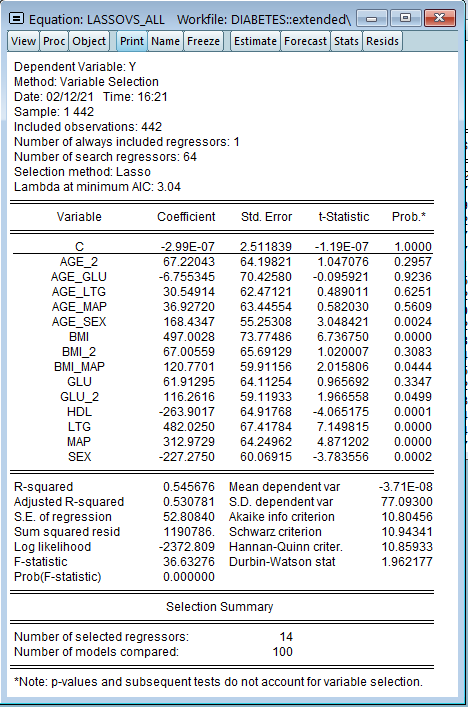
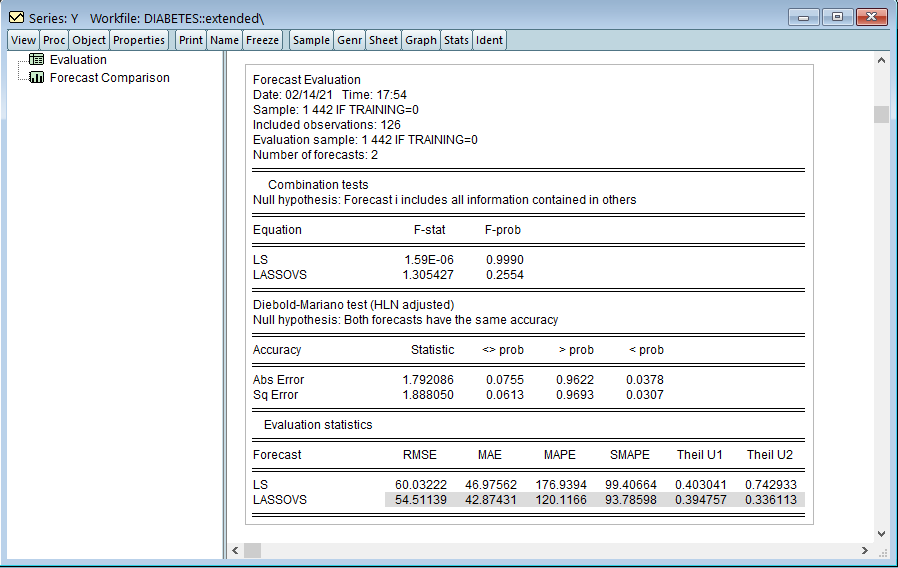
LASSO変数選択モデルの真の実力はさらに大きな(高次元の)データセットで推定を行う際に発揮されます。これを確認するため、二乗した9変数と54の交差項を使用して合計64の独立変数を使用します。

ISO27001(ISMS)認証
情報セキュリティ・マネジメントシステム

© 2026 Lightstone Corp. All Rights Reserved