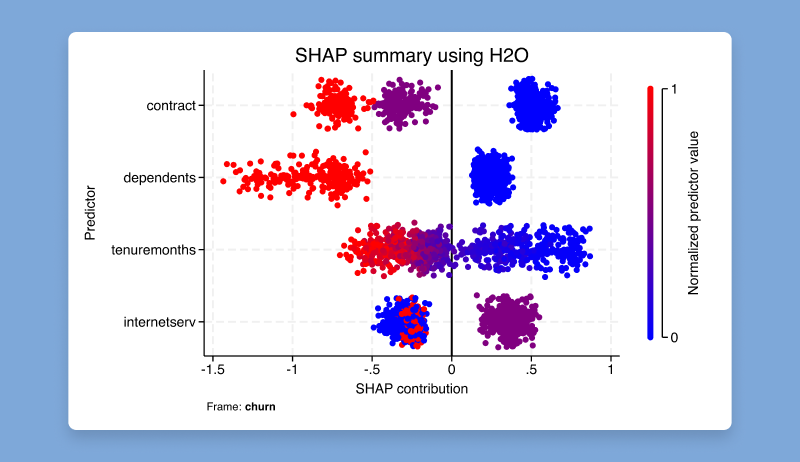
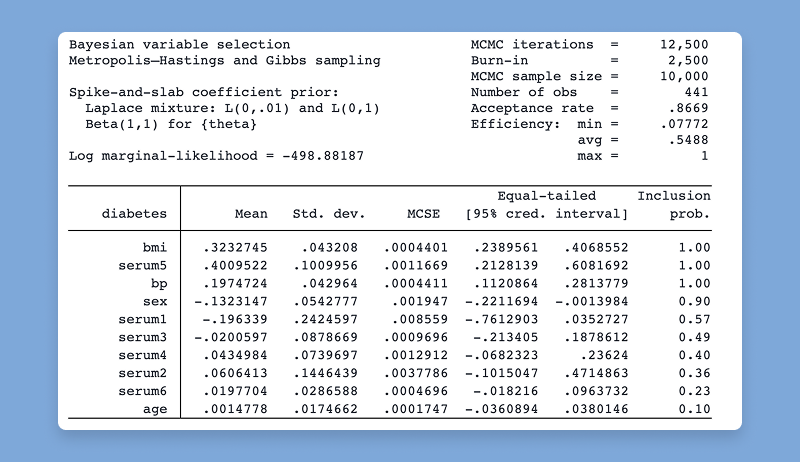
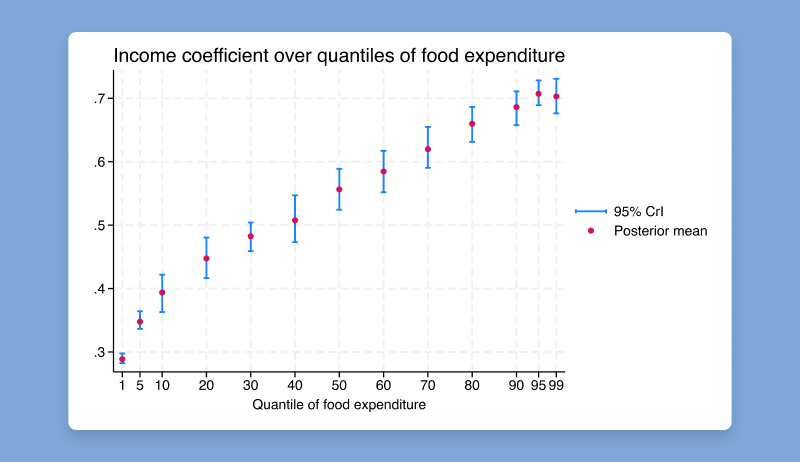
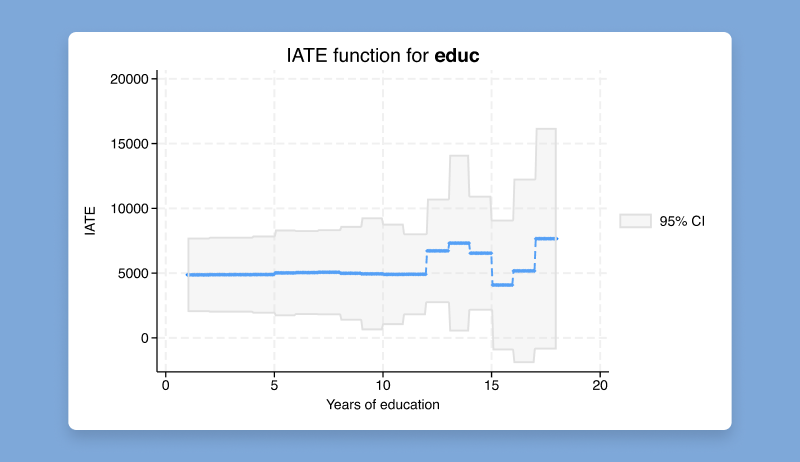
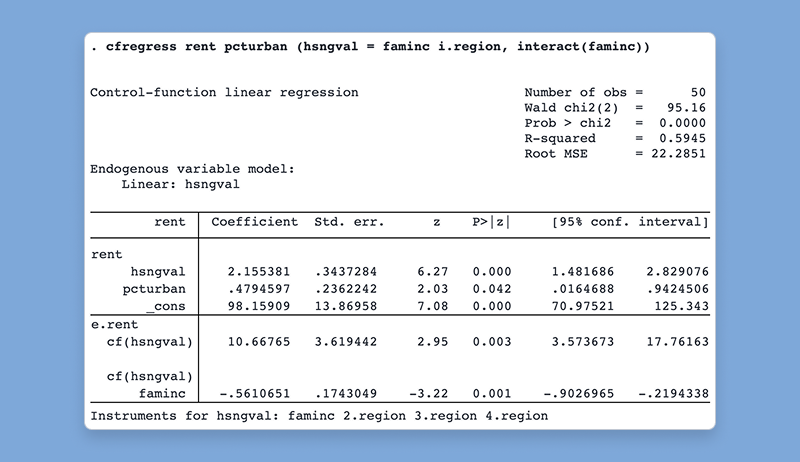
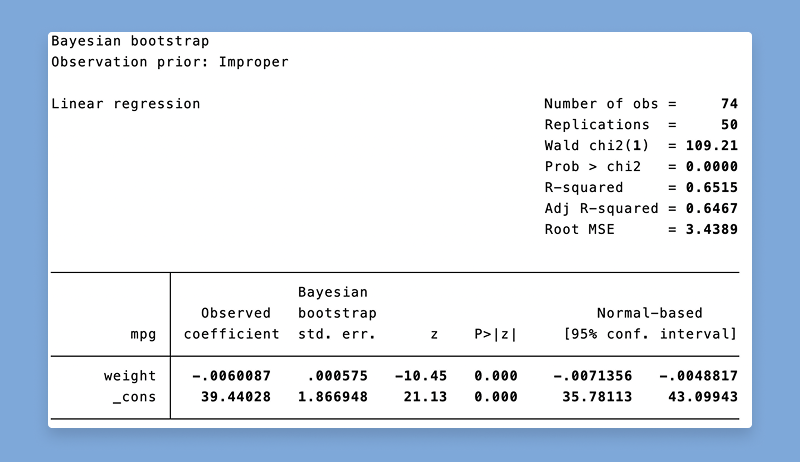
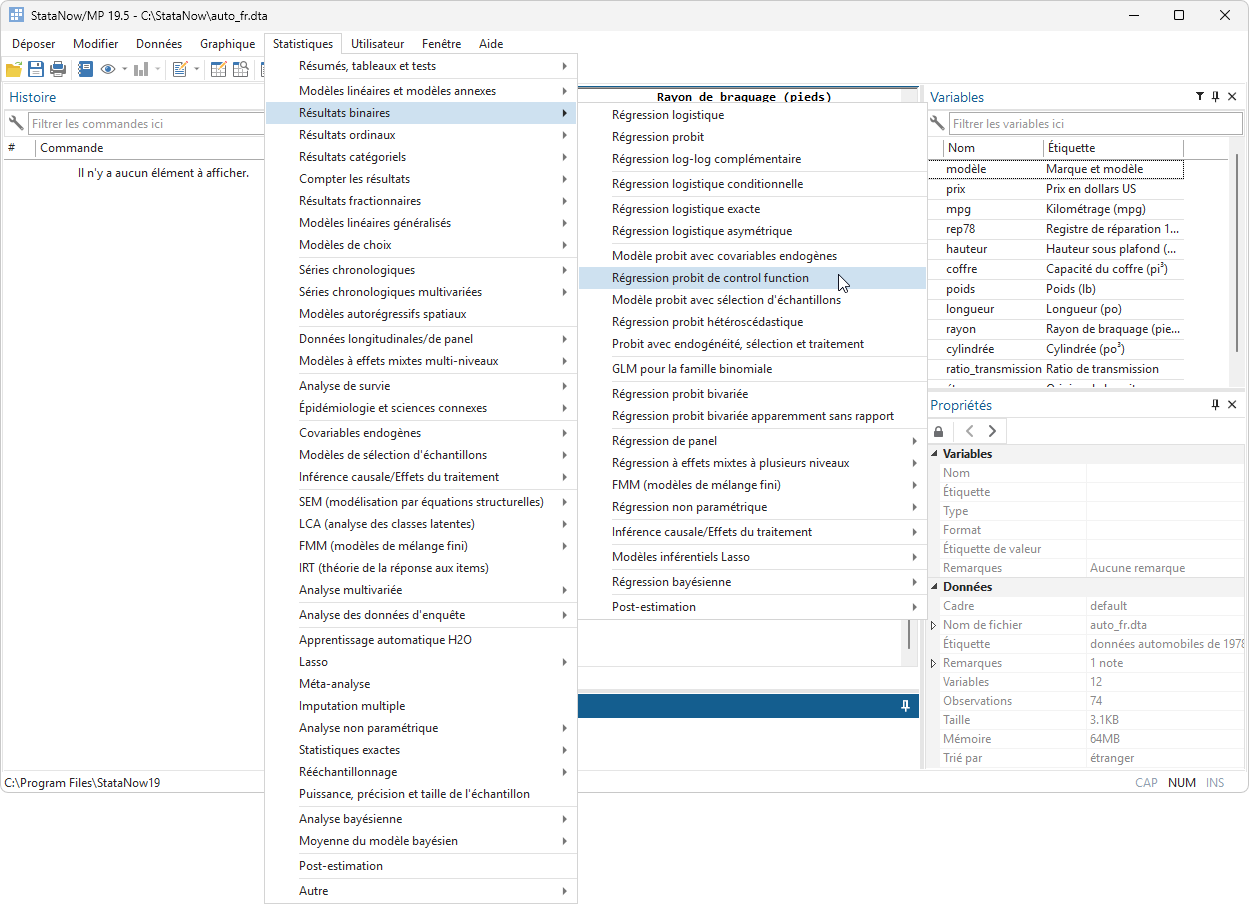
ivsvar は、操作変数を使用して SVAR モデルのパラメーターを推定します。
これらの推定パラメータは、構造インパルス応答関数 (IRF) として知られる動的な因果効果を追跡するために使用できます。
これらの IRF は、SVAR モデルへのショックが時間の経過とともにモデル変数にどのような影響を与えるかを説明します。
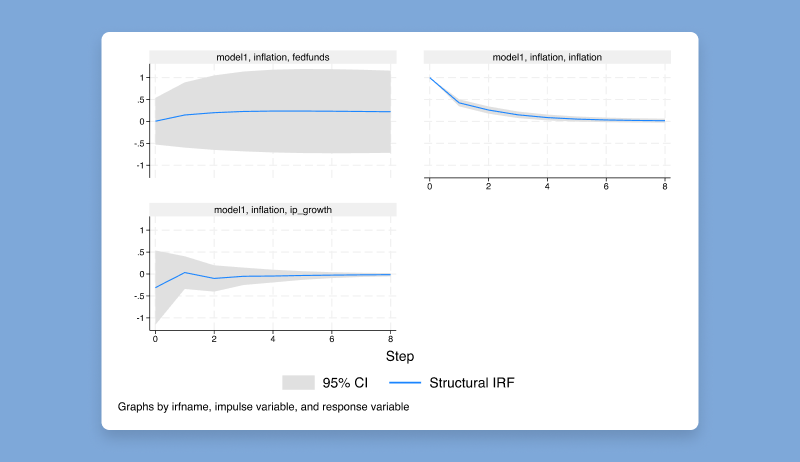
bayesmh コマンドには、新しい尤度関数として非対称ラプラス分布 (ALD) が
含まれるようになりました。 ALD を使用すると、顕著な歪度と尖度を伴う非正規の結果をモデル化できます。
ベイジアン分位点回帰モデルの適合にも使用できます。
Doファイルでは以下の機能が追加されました。
xtreg コマンドの新しいオプション cre を使用して、パネルデータの相関変量効果(CRE)モデルを簡単に適合させることができます。
CREモデルは、個々の異質性と説明変数の間の相関から生じる内生性バイアスに対処するのに役立ちます。
実際、CREモデルで時間とともに変化する変数の係数は、固定効果(FE)モデルから得られる係数と数値的に等価です。

推定後コマンド estat mundlak は、ランダム効果推定と固定効果推定の間の選択を支援するための完全にロバストなMundlak適合度検定を実装します。
Mundlak検定は、Hausman検定などの他の検定とは異なり、ロバスト推定、ブートストラップ、およびジャックナイフ標準誤差の推定後にも実施することができます。
estat mundlak は、re、cre、fe オプションを使用した xtreg コマンドの実行後に使用することができます。

新しい推定コマンド xtvar は、パネルデータに VAR モデルを適合させます。
システム内の各従属変数は、その変数自体のラグ、他のすべての従属変数のラグ、
およびパネルレベルの固定効果の関数としてモデル化されます。他の説明変数もモデルに追加できます。
これらの変数は、事前に決定されたもの、完全に外生的なもの、または内生的なものにすることができます。
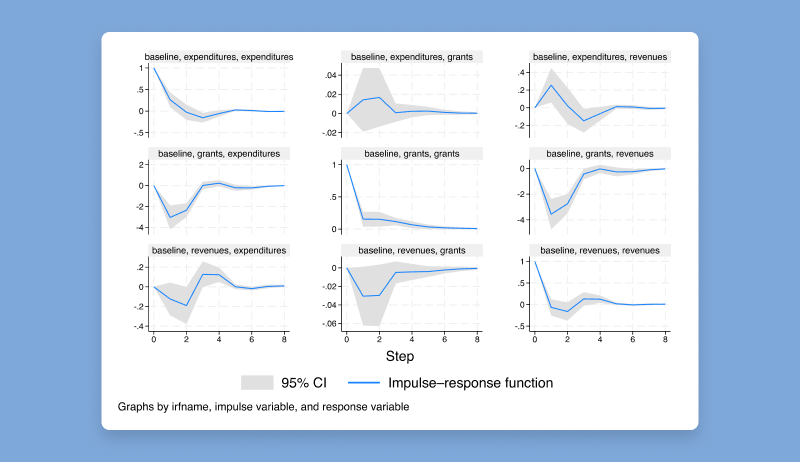
新しい推定コマンド ivlpirf は、局所射影モデルを適合させて
IRFを推定し、目的のインパルス変数の内生性を考慮するために操作変数を使用します。
局所射影は、結果変数に対するショックの影響を推定するために使用されます。
関心のあるショックが内生的である可能性のあるインパルス変数に及ぶ場合、 ivlpirf
を使用してIRFを推定でき、インパルス変数は1つ以上の外生的操作を使用して操作できます。
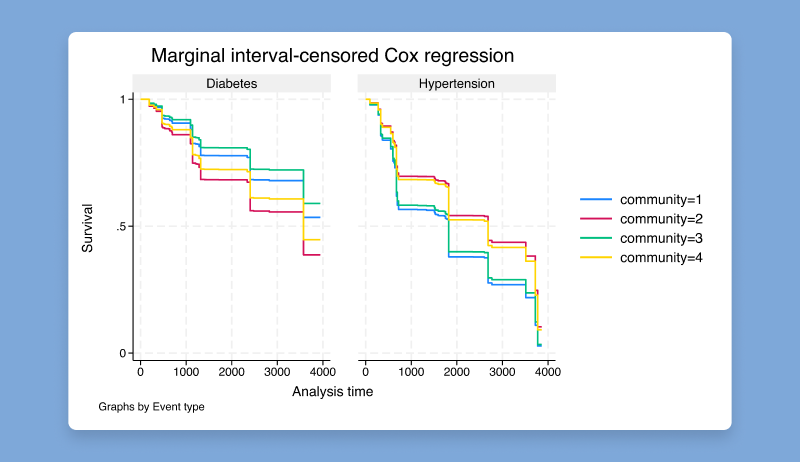
区間打ち切りされた複数イベントデータは、長期的な研究でよく発生します。
なぜなら、各研究対象者が複数の種類のイベントを経験する可能性があり、これらのイベントは直接観察されることはなく、
特定の時間区間内に発生したことだけが知られているからです。
新しい推定コマンド stmgintcoxを使用すると、このようなデータに対して
限界的なCox比例ハザードモデルを適合させ、複数のイベントの間のイベント発生時刻の依存性を考慮することができます。
このコマンドは、単一イベントまたは複数レコードごとのデータにモデルを適合させることができ、
すべてのイベントまたは特定のイベントに対して時間変動共変量をサポートします。
また、stmgintcox は、イベント固有の共変量を指定する柔軟な方法も提供します。
ivregress コマンドでの推定後に estat weakrobust コマンドを使用して、
内生変数に対して Anderson-Rubin 検定または条件付き尤度比 (CLR) 検定を実行します。
estat weakrobust は、内生変数が 1 つの場合に、関連する信頼区間を算出できます。

ベクトル自己回帰 (VAR) モデルをフィッティングするための
var コマンドで、vce(robust) オプションを使用してロバストな標準誤差を推定できるようになりました。
Stata is a registered trademark of StataCorp LLC, College Station, TX, USA, and the Stata logo is used with the permission of StataCorp.

ISO27001(ISMS)認証
情報セキュリティ・マネジメントシステム

© 2026 Lightstone Corp. All Rights Reserved