
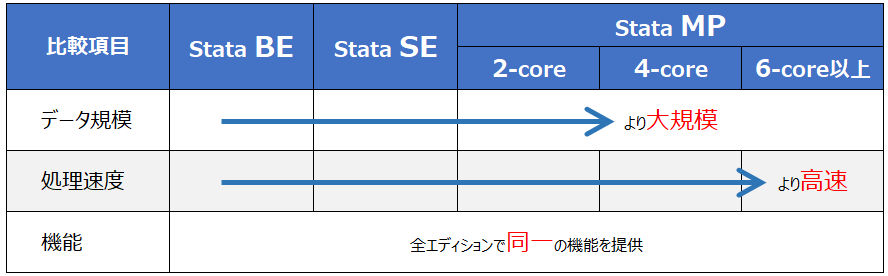
Stataのエディション
Stataには、取扱うデータの規模と計算する処理速度の異なる3つのエディションがあります。
機能やサポートされるコマンドの種類に違いはありません。



Stataには、取扱うデータの規模と計算する処理速度の異なる3つのエディションがあります。
機能やサポートされるコマンドの種類に違いはありません。
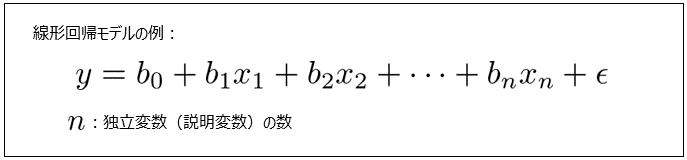
Stata/MPはお使いのコンピュータのマルチコアプロセッサ機能を活用することにより、計算を並列に行います。それによりコマンドによっては実行速度がかなり向上します。
| コア数 | 全てのコマンド | 推定コマンド | ロジスティック回帰 |
|---|---|---|---|
| 2 | 1.6倍 | 1.7倍 | 2.0倍 |
| 4 | 2.3倍 | 2.6倍 | 3.8倍 |
| 8 | 2.9倍 | 3.4倍 | 6.9倍 |
| ※上記の数字はスピードアップした要素の中央値です。実際にはコマンドによって上記の数字よりも早く、または遅くなります。 | |||
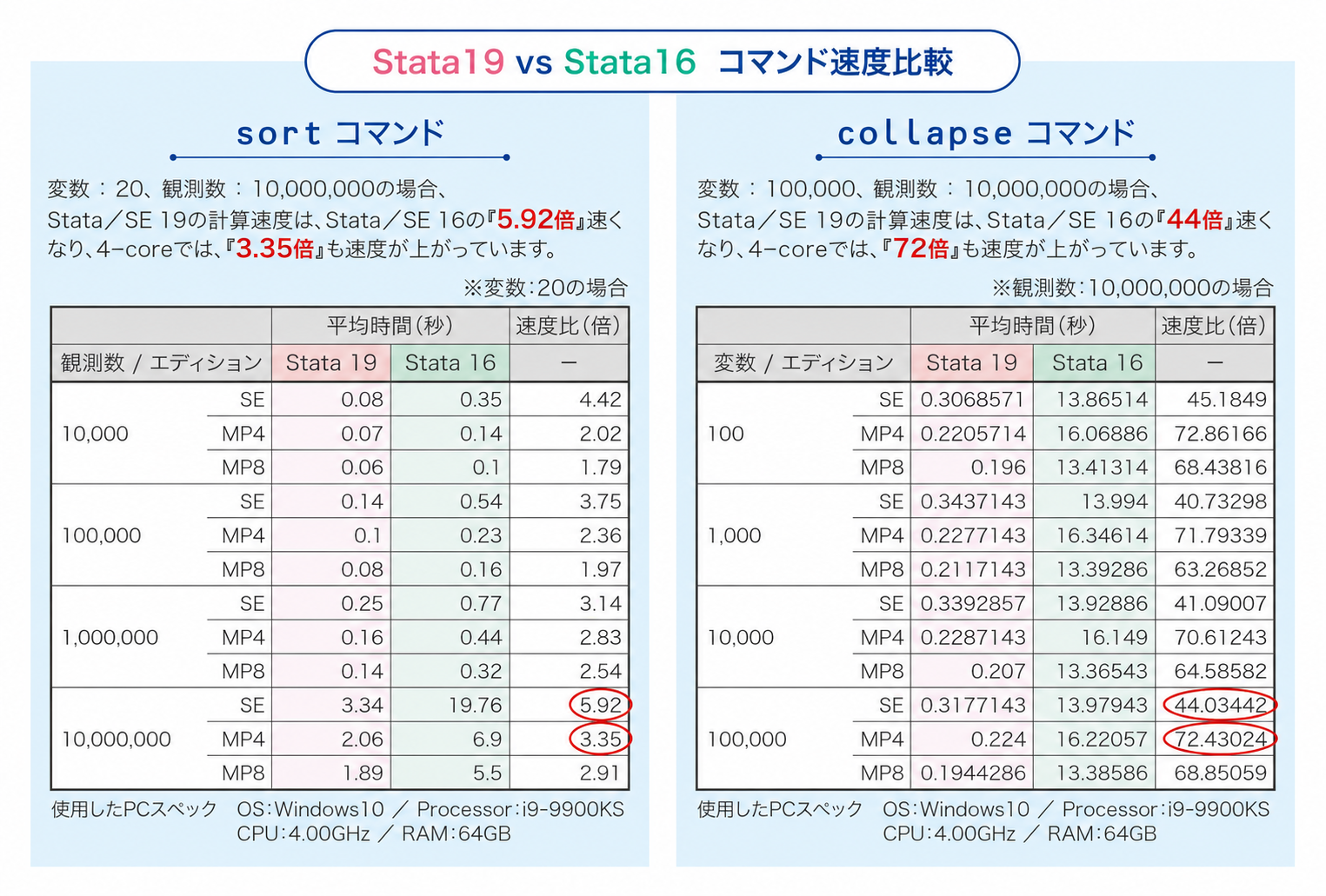
マルチコアCPUやマルチプロセッサの機能を使用して並列処理を行うことにより、Stata/BEやStata/SEよりも高速に分析を行うことができます。
処理速度変化はコマンドにより異なりますので、下記のテスト結果をご参照ください。
| 機能 | Stata / BE |
Stata / SE |
Stata / MP (2-core) |
Stata / MP (4-core) |
Stata / MP (6-core以上) |
|---|---|---|---|---|---|
| 変数の上限数(列数) | 2,048 |
32,767 |
120,000 |
120,000 |
120,000 |
| 観測データの上限数(行数) | 21.4億* |
21.4億* |
200億* |
200億* |
200億* |
| 回帰式における独立変数(説明変数)の上限数 | 798 |
10,998 |
65,532 |
65,532 |
65,532 |
| マルチコア対応
ロジスティック回帰分析の演算時間 (観測数:1,000万、共変量の数:20) |
1-core 20秒 |
1-core 20秒 |
2-core 10秒 |
4-core 5.2秒 |
6-core以上 5.2秒未満 |
| 全ての統計解析機能の利用 | |||||
| 印刷品質のグラフ作成機能 | |||||
| 解析の再現性 | |||||
| レポートと表の生成 | |||||
| 行列プログラミング言語の使用 | |||||
| PDF形式のマニュアルセットの提供 | |||||
| 無償テクニカルサポートの利用 | |||||
| サービスリリースの提供 | |||||
| Windows, macOS, Linux 全サポート |
※取扱えるデータ量は実装メモリの容量により制限されます。特にStata/MPについては、現在この観測データ上限数を賄えるメモリを備えたコンピュータがほとんど市販されていないため、取扱えるデータ量はメモリの容量の限界までとなります。
Stata is a registered trademark of StataCorp LLC, College Station, TX, USA, and the Stata logo is used with the permission of StataCorp.

ISO27001(ISMS)認証
情報セキュリティ・マネジメントシステム

© 2026 Lightstone Corp. All Rights Reserved
{kind=link}
{kind=link}