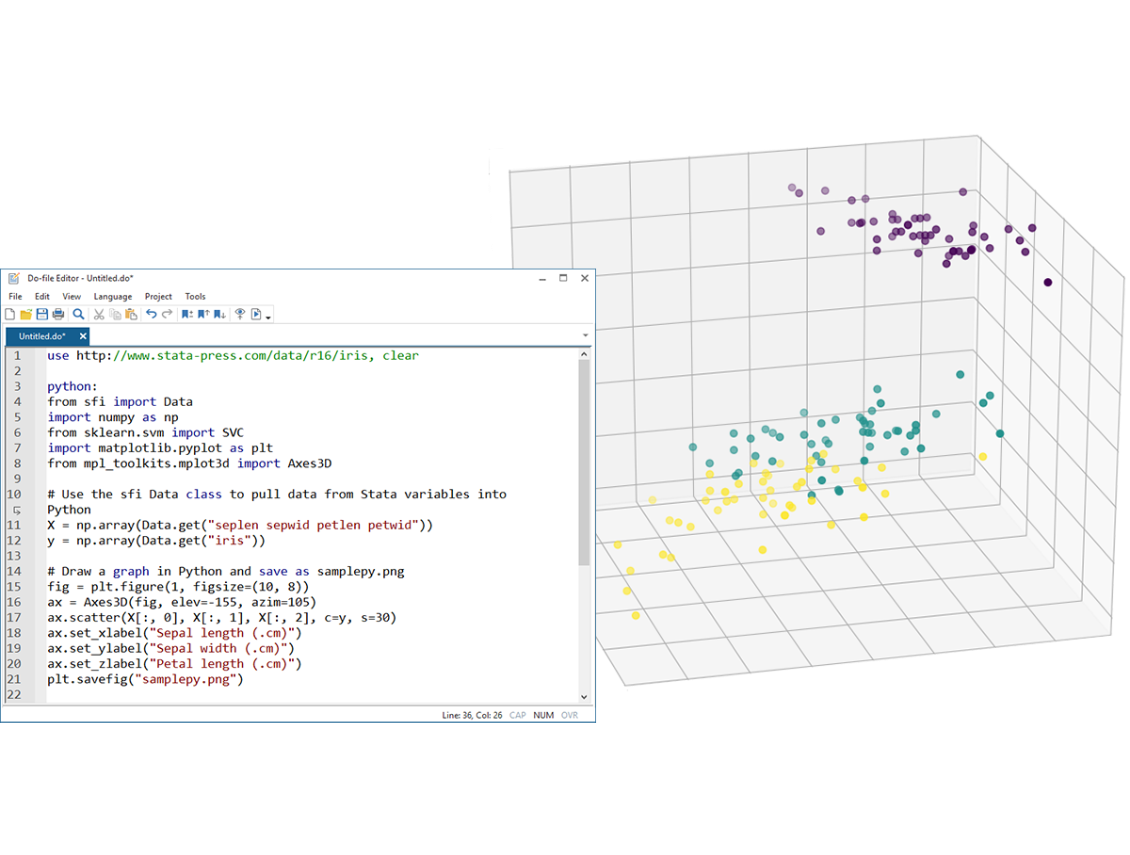
Lassoはモデル選択、予測、そして統計的推測に利用可能な技術です。新しいlassoコマンドを利用する事により連続、頻度、二値のアウトカムを取り扱う線型、ポアソン、ロジット、プロビットの回帰モデルで最適な予測値の計算が可能となります。Stata16のlassoコマンドでは変数の選択だけでなく、係数、標準誤差、信頼区間の推定、そして係数の診断まで11のコマンドが用意されています。
例えば、次のようなコマンドを実行します。
. lasso linear y x1-x500
lassoは変数群の中から例えば最適なフィットを実現するx2, x10, x11, x21の変数セットを選択します。そこで標準的なpredictコマンドを実行することでyの予測値を計算します。
二値データや頻度データをアウトカムとする場合はlasso logit, lasso probit, lasso poissonといったコマンドを実行します。変数選択で elastic net や square-root lasso 法を利用する場合はelasticnet やsqrtlassoといったコマンドを利用します。新たに提供されるコマンドは次の通りです。
dsregress, dslogit, dspoisson, poregress, pologit, popoisson, poivpoisson, xporegress, xpologit, xpopoisson, xpoivregress
dsで始まるコマンドは二重選択型lassoコマンドです。poは部分選択型、xpoはクロスフィットによる部分選択型のlassoコマンドを意味しています。アウトカムの種類は連続、二値、頻度に対応しています。アウトカムが連続変数である場合は、内生変数を含むモデルでも利用可能です。lassoベースの統計的推測の手法には様々な提案があり、今回、できるだけ多くの手法を新たにサポートしました。
lassoとelasticnetは変数選択と予測に利用されるコマンドです。統計的推測に利用するlassoの新しいコマンド群は元々、計量経済学者によって開発された手法ですが、今日では係数の診断と解釈を必要とする様々な分野の研究者にとってニーズの高い分析手法となっています。
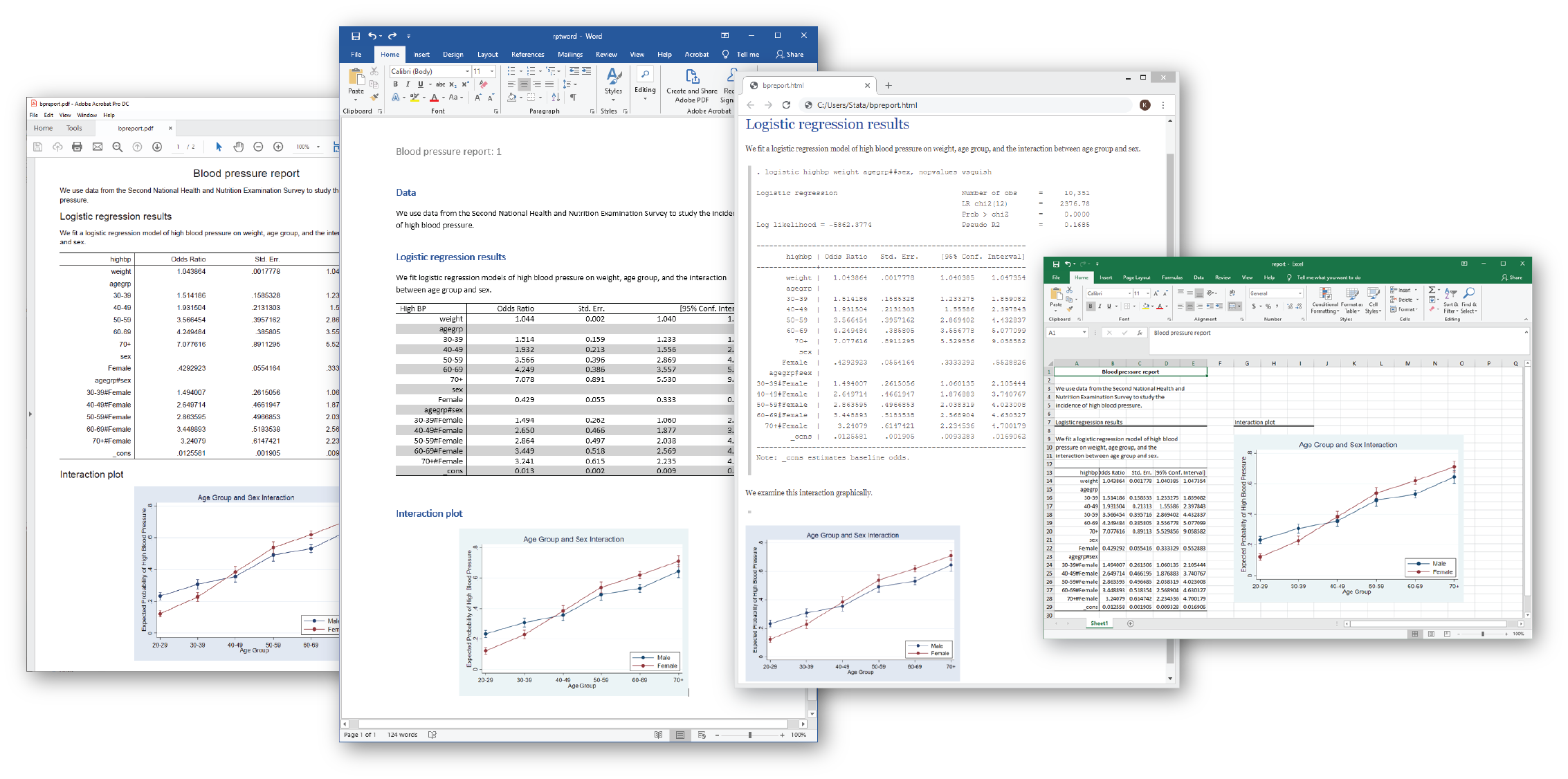
Stataのレポート機能では、Stataから出力した結果やグラフ、表をWordやPDF、Excel、HTML文書として作成できます。Stata 16では作成したファイルの種類を問わず、データの変更に伴って更新される動的なレポート機能を新たに用意しました。更新済みのデータセットを準備して、コマンドやdoファイルを再実行するだけで、更新されたレポートが自動的に作成されます。
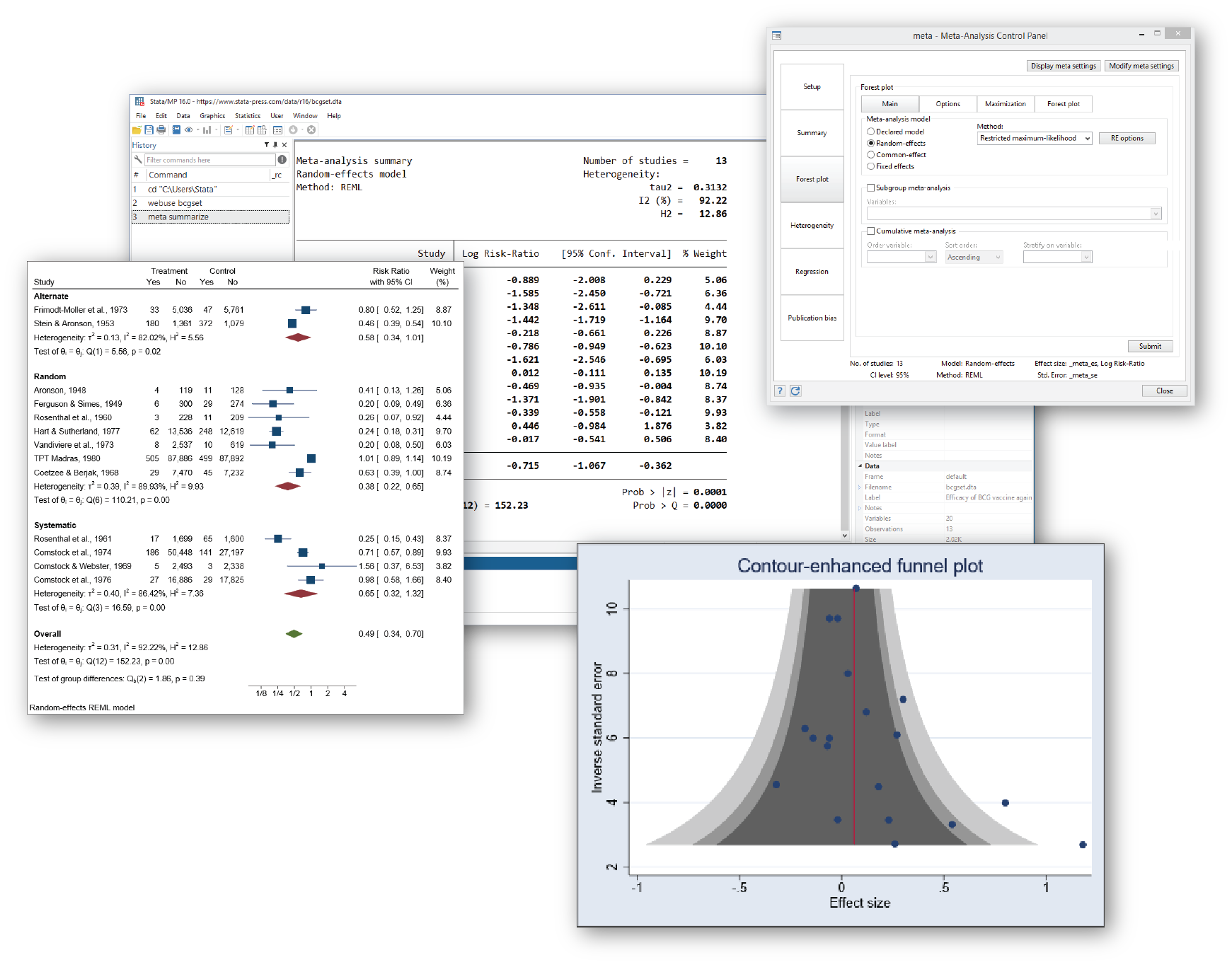
Stata 16はメタ分析用のコマンドセットを新たに用意しました。これにより一次研究の効果量を統合して考察することが可能になりました。例えば、血圧に一定の効果を与える事を報告している20本の一次研究を集め、メタ分析により統合した効果量を求めることができます。メタ分析は従来からadoファイルにより実行可能でしたが、純正コマンドによって使い勝手を向上させました。
metaコマンドのセットは豊富な機能と使いやすさを両立しました。メタ分析を行う際は次のような設定を最初に行います。
. meta set effectsize stderr
統合した効果量とその信頼区間を推定する時は統計的異質性を確認したり、統合の結果を視覚的に表現するために、フォレストプロットを作成できます。
meta のコマンドセットはこれだけではありません。 メタ回帰分析とサブグループ分析は一次研究の異質性を評価する用途にも利用可能です。 これらの分析を行うためにmeta regress, meta forestplot, subgroup(), meta summarize, subgroup()などのコマンドセットが用意されています。
潜在的な出版バイアスを調べることもできます。一次研究の非対称性を視覚的に捉えるファンネルプロットの作成にはmeta funnelplot, 非対称性の仮説検定はmeta bias,非対称性をもたらしている一次研究の欠落を補って出版バイアスを調査するコマンドmeta trimfillを用意しました。累積メタ分析の実行には meta summarize, cumulative()を利用します。
Stata 16では選択データモデリングのための統一されたコマンドが導入されました。選択データを要約する新しいコマンドが追加され、既存の選択モデルコマンドも改良され、コマンド名が変更されました。さらに、パネルデータを用いた混合ロジットモデルのコマンドが追加され、機能を詳しく解説したChoice Models Manualを用意しました。
選択モデルに用いられるcm推定コマンドは次の通りです。
そして、cmsummarize, cmchoiceset, cmtabおよびcmsampleのそれぞれのコマンドで、データの確認、要約、さらに潜在的な問題を検討します
選択モデルでは、フィット結果を解釈するのにmarginsコマンドがとても有効です。選択モデルで推定された係数はほとんどの場合、解釈が難しいものですが、marginsコマンドならば、推定された結果に基づいた特定の問いを立て、それに対する答えを得ることができます。例えば次のようなものです。
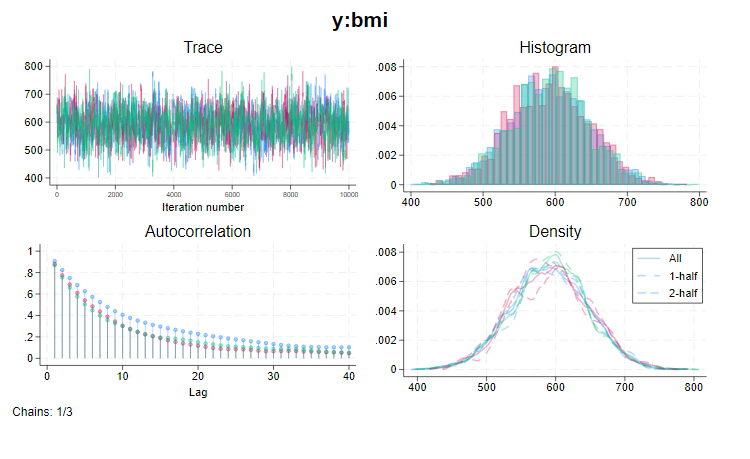
マルコフチェーンの計算が収束した場合に限りMCMC(マルコフチェーンモンテカルロ)法によるベイズ推定の結果は適切であると考えることができます。収束状態を判断する方法の一つとしてシミュレーションで複数のチェーンを比較するという方法があります。Stata16ではbayes:プリフィックスとbayesmhコマンドに新たにnchains()オプションを追加しました。
例えば次のように入力します。
. bayes, nchains(4): regress y x1 x2
このコマンドにより4つのチェーンが作成されます。この4つのチェーンを組み合わせてより高精度な推定結果を求める事も可能ですが、それらのチェーンを視覚的に比較して収束状況を確認します。収束の確認にはGelman–Rubin の診断法が利用できます。複数チェーンのシミュレーションを実行したあとでbayes: regress など、いくつかの推定コマンドを実行すると、この診断結果も報告されます。収束しない事に関心がある 場合はbayesstats grubin コマンドを利用します。これはモデルに含まれる各パラメータに対して個別にGelman–Rubinの診断を実行します。
ベイズ予測とは事後予測分布を利用してシミュレーションを行うものです。この手法はモデルのフィットを吟味し、アウトオブサンプルの予測に適しています。bayesmhコマンドでモデルをフィットした場合、bayespredict コマンドを利用することでシミュレーションの予測値やその関数を計算し、それらを新たなデータセットとして保存できます。例えば次のように入力します。
例えば次のように入力します。
. bayespredict (ymin:@min({_ysim})) (ymax:@max({_ysim})), saving(yminmax)
このコマンドはシミュレーションした値の最大/最小値を求めます。この他にも予測値の要約統計量を調べる場合にbayesgraphなどの推定後に利用するコマンド群が用意されています。
bayespredictコマンドは数千個のシミュレーション値から新たなデータセットを作成します。もちろん、全てのシミュレーション値が必ずしも必要とは限りません。そのようなケースでは事後分布による要約統計量として平均や中央値などをbayespredict, pmean, bayespredict, pmedianといったコマンドで求めることができます。また、シミュレーション値からのランンダムサンプリングもサポートしています。
モデルの適合度を評価する場合には、事後分布による予測p値(PPP/ベイズ予測p値)を利用します。PPPは観測値とシミュレーション値の一致度を計測する指標であり、新しいコマンドbayesstats ppvaluesを用いて求めます。
Stata16に新しく追加されたnpregress series は多項式、Bスプライン、または、共変量を利用したスプライン関数を用いて、被説明変数の平均値に対するノンパラメトリックなシリーズ回帰を実行します。ユーザが関数形を指定する必要はなく、モデルで利用する変数を選択するだけです。
例えば、次のコマンドを実行します。
. npregress series wineoutput rainfall temperature i.irrigation
このコマンドを実行しても係数が出力されることはありません。npregress seriesコマンドは連続変数の場合は平均限界効果を、そしてカテゴリー変数の場合は対比を報告します。例えば、降雨量rainfallの平均限界効果が1で灌漑irrigation の対比が2であるとします。この時の対比は灌漑の平均処置効果として理解できます。
ノンパラメトリック回帰の場合、平均値が不明な変数については共変量のシリーズ関数で近似を行います。それだけに留まらず、パラメトリックモデルを利用して統計的推測を行うこともできます。その場合は次の示すようにmarginsコマンドを利用します。
Stata is a registered trademark of StataCorp LLC, College Station, TX, USA, and the Stata logo is used with the permission of StataCorp.

ISO27001(ISMS)認証
情報セキュリティ・マネジメントシステム

© 2026 Lightstone Corp. All Rights Reserved