
欠損値に対する多重代入
Stataの新たな mi コマンドは不完全なデータ(一部の値が欠落しているデータ)を分析する際に用いられる多重代入法の機能を提供します。mi には代入に関するステップと推定に関するステップの双方が含まれています。mi の推定ステップは個々のデータセットに対する推定機能に加えて、簡単な操作手順でプーリングする機能もカバーしています。またデータ中の欠損値のパターンを調べる機能も用意されています。柔軟な代入手法が用意されていますが、その中には5種類の単変量代入法(多変量代入のための構成要素として使用可能)の他に多変量正規(MVN)代入法が含まれています。
mi は既に代入済みのデータをインポートする機能の他に、それらの管理に必要な機能も一式用意しています。
多重代入 - 推定機能
今、y と説明変数 x1, x2 間の線形関係を調べたいものとします。しかしデータには欠損値が含まれているため、標準的なケース単位の削除手続き(casewise deletion)では標本サイズが40%も減ってしまうという問題が発生します。そこで多重代入(MI: multiple imputation)の機能を用いてモデルのフィットを行うことにします。
最初に欠損値の代入を行い、5つの代入データセットを作成します。
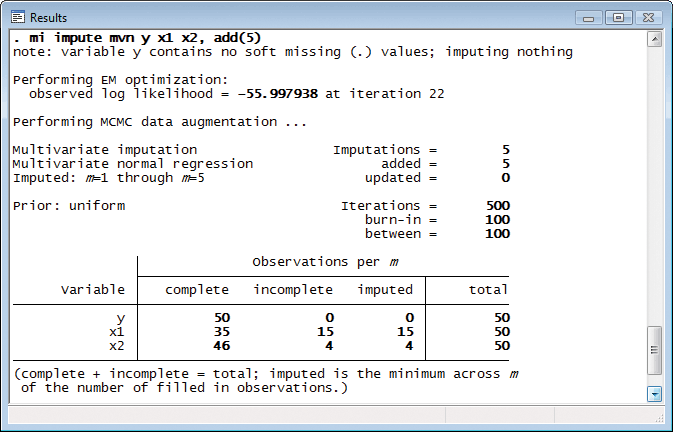
次にモデルのフィットを行います。
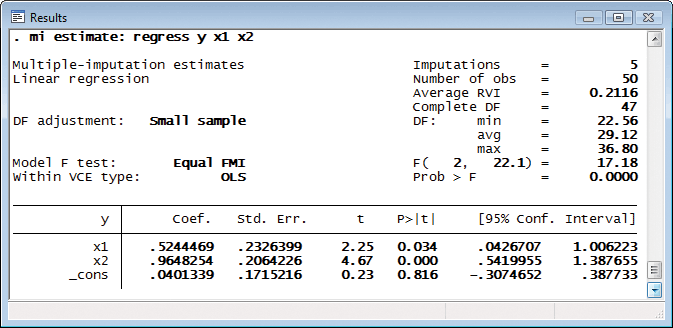
mi estimate はそれぞれの代入データセット(今の場合、5種類)に対して指定されたモデル(ここでは線形回帰)をフィットさせ、次にそれらの結果を一つにまとめた形でMI推論を行います。
多重代入 - 基本要素
mi は NHANES または ice の形式の代入済みデータをインポートすることができますが、オリジナルのデータから始めて代入データを自分で構成することもできます。
いずれにせよ、複数コピーのデータを扱うことはトラブルの元となるため、mi ではそれに対する対処がなされています。すなわち mi は wide, mlong, flong, flongsep という4種類の形式のいずれかの形にデータを編成します。flongsep 形式の場合には、それぞれの代入データセットは単独のファイルとなります。その他の形式の場合、データは一つのデータセットに結合されます。それぞれの形式にはそれぞれ独自の長所がありますが、形式を切替えることも mi では容易に行えます。それぞれの処理ごとに最適な形式を用い、形式を切替えながら処理を進めて行くといったアプローチを取ることができます。
すべての mi コマンドはこれらすべての形式に対応しています。
データ管理機能も一式提供されています。通常のデータセットに対する操作と同様の形で変数の生成や削除、あるいは観測値の生成や削除が行えます。それぞれの代入データセットにそれらを正しく反映させる操作は mi が自動的に行います。MIデータを他のデータセット(通常のもの、またはMI)と merge させたり、append させたりことができます。また代入された値を別のデータセットにコピーすることもできます。生存データを扱っている場合には、通常の場合と同じように、時間帯の split や join が行えます。パネルデータを扱っている場合には、通常の場合と同じように、reshape 操作を行うことができます。ある操作に伴い、5個、50個、あるいは500個のデータセットに対して同じ操作が必要となったとしても、操作上は見えません。
多重代入 - 制御パネル
mi の制御パネルを利用することによってMI関連の一連の操作をスムーズに行うことができます。
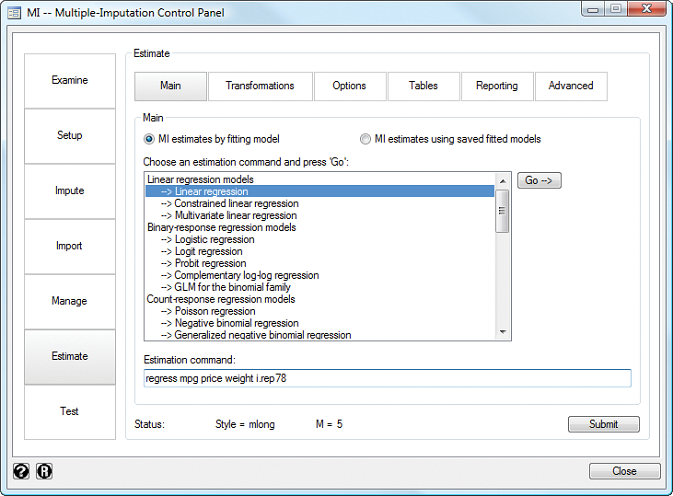 この制御パネルは数多くの
mi
の機能を統一的なインタフェースで提供するものです。欠損値とそのパターンの調査といった最上流の過程から最下流のMI推論の過程に至るまで、一貫した形でサポートしています。
この制御パネルは数多くの
mi
の機能を統一的なインタフェースで提供するものです。欠損値とそのパターンの調査といった最上流の過程から最下流のMI推論の過程に至るまで、一貫した形でサポートしています。
欠損値のパターンをチェックし適切な代入法を決定するためには、Examine ツールを使用します。
データを mi で扱えるようにするためには Setup を使用します。
代入操作を行うためには Impute を使用します。
既に代入操作が済んでいるのであれば Setup をスキップ、直接 Import に進んでインポート操作を行います。
mi データに対して新変数の生成、データの merge や reshape、その他のデータ管理コマンドを使用する場合には、Manage パネルを利用します。
準備が整ったら Estimate を用いてモデルの選択を行います。用意されているダイアログタブを利用することによって、MI推定モデルを簡単に構築することができます。
Test パネルを使用すると仮説検定の機能を実行させることができます。
多重代入 - 機能
- 代入機能
- 単一の変数中における欠損値に対して次の手法のいずれかによって代入を行います。
- 連続変数に対する線形回帰法(パラメトリック)
- 連続変数に対する predictive mean matching 法(部分的パラメトリック)
- 2値変数に対するロジスティック回帰法
- 順序変数に対する順序ロジット法
-
名義変数に対する多項ロジスティック法
-
上記5手法を任意に組み合わせることによって、単調な欠損値パターンを有する複数変数中の欠損値に対して代入操作を行うことができます。(例えば
x1 に対しては predictive mean matching 法を、x2 に対しては順序ロジスティック法を用いて、x1,
x2 双方に対する代入操作が行えます。)
代入された変数に対する予測方程式をカスタマイズすることができます(例えば x1 に対するモデルから z2 を省略するなど)。
変数ごとに異なる観測値を用いて欠損値の代入操作が行えます(例えば1日当りの喫煙量については喫煙者のみを対象として、一方、体重については全観測値を対象に欠損値の代入を行うなど)。
代入変数に対する数式中で既に代入済みの変数を含む数式を使用できます(例えば x1 に対して代入を行った後、x2 に対する代入モデル中で x12 を含めるなど)。
- 任意の欠損値パターンを持つ複数変数に対しては MVN モデルを用いた欠損値の代入が行えます。
- 既に代入操作が行われた状態であっても、代入データセット数を増やすといった変更操作が可能です。
- 重み付きデータやサーベイ重み付きデータに対しても MVN を除く上記すべての手法が適用できます。
- 任意の欠損値パターンを持つ複数変数に対しては MVN モデルを用いた欠損値の代入が行えます。
- 単一の変数中における欠損値に対して次の手法のいずれかによって代入を行います。
- 推定機能
- 個別の推定と結果のプーリングを1ステップで実行します。
-
生存データ回帰モデルやサーベイデータ回帰モデルを含め、Stataのほとんどの推定コマンドを用いてモデルのフィットが行えます。
-
変換されたパラメータのMI推定値を算出します。
- 過去に保存した個別の推定結果からMI推定値を算出します。
-
欠損情報の割合や相対的な効率等、MI特性に関する詳細情報を算出します。
-
ユーザが作成した推定法を用いて推定を行うこともできます。
-
mi
は代入操作を通じて推定モデルの正当性(推定標本と省略変数の一致性、モデルの収束性)を検証し、問題が存在する場合にはその旨通知します。
- 個別の推定と結果のプーリングを1ステップで実行します。
- 事後推定機能
- 複数の係数値に関し同時に検定を実行します。
- 欠損情報の割合が均一/不均一との仮定のもとでの検定が行えます。
-
小標本補正の機能が用意されています。
- 複数の係数値に関し同時に検定を実行します。

