記述統計の表
論文・レポートを公開するときは、「表 1」と呼ばれる記述統計の表でデータセットの要約を行うことが一般的です。
これにより、読者は標本に関する情報を得ることができます。 たとえば、平均年齢や平均収入などの人口統計を表示したい場合があります。 これらの特性を、地域や職業分野などのグループ間で比較することもできます。
Stata 18 では、dtableコマンド を使用して、「表 1」のこれらおよび他の多くのバリエーションを作成し、それらを多くの形式にエクスポートできます。 たとえば、表を作成して Excel にエクスポートできます。
または、表を作成して HTML にエクスポートすることもできます。
ワード形式
またはPDFもサポートしています。
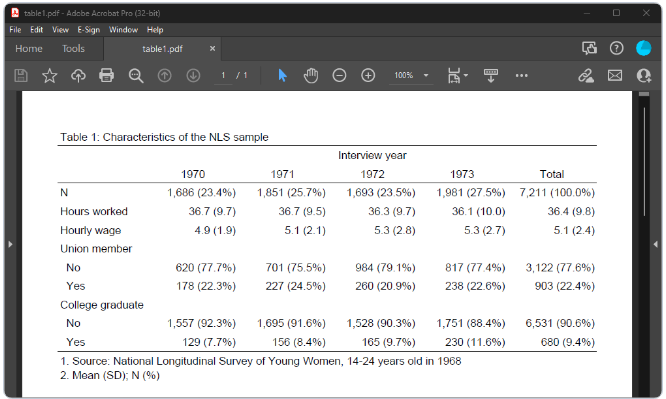
また、dtable は、任意のタイプの表をカスタマイズするために設計された collect コマンド スイートに基づいて構築されているため、dtable を使用して表を作成した後、
collect コマンドを使用して表の外観をさらにカスタマイズできます。
操作例
dtable を使用すると、表に必要な変数を指定するだけで、記述統計量の表を簡単に作成できます。 dtable は、1 つのステップで表を作成してさまざまな形式にエクスポートできるように設計されています。
連続変数については平均値と標準偏差が報告され、因子変数については度数とパーセンテージが報告されます。これだけあれば、エクスポート先のファイル名とファイル形式を指定するだけで完了です。
もちろん、さまざまな統計を含めたり、さまざまなテストを実行してグループ間の同等性を確認したり、タイトルやメモを追加したり、その他の変更を加えたりして、表をカスタマイズできます。
以下の例では、記述統計の表を作成、変更、およびエクスポートする方法について説明します。
簡単な例
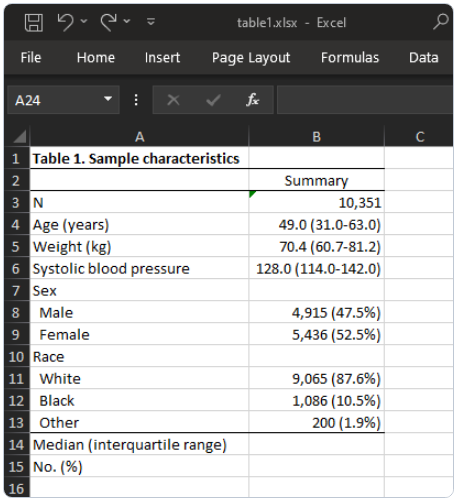
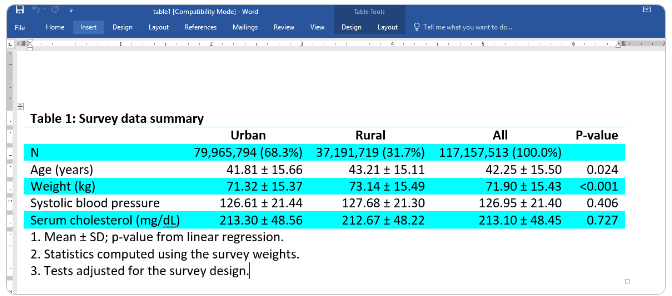
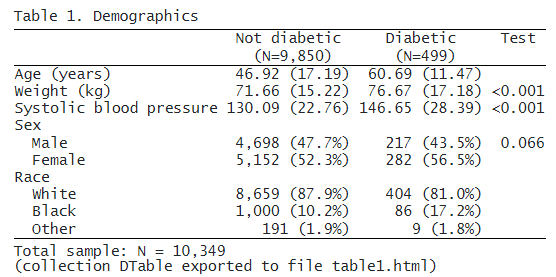
まず、第 2 回国民健康栄養調査 (NHANES II) (McDowell et al. 1981) からデータを読み込みます。 指定された変数の要約統計量が必要ですが、糖尿病のカテゴリごとに個別に必要です。 因子変数表記法を使用して、性別と人種がカテゴリ変数であることを示していることに注意してください。 そして、表をファイル table1.html にエクスポートします。
. webuse nhanes2l, clear
. dtable age weight bpsystol i.sex i.race, by(diabetes) export(table1.html, replace)
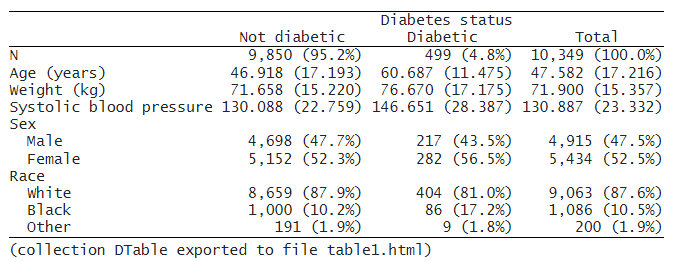
これは、表の作成とエクスポートがいかに簡単かを示しています。 この表を LaTeX や PDF などの別の形式にエクスポートする場合は、適切なファイル拡張子を指定するだけです。 これは有益な表ですが、以下でさらにカスタマイズします。
デフォルトでは、dtable は連続変数の平均と標準偏差、および因子変数の度数とパーセンテージを報告します。 標本の約 95% が糖尿病ではなく、5% が糖尿病であることがわかります。
また、非糖尿病グループの平均収縮期血圧が 130 で、糖尿病グループの平均が 147 であることもわかります。平均収縮期血圧が糖尿病の状態によって異なるかどうかをテストできます。
また、性別と糖尿病状態が独立しているかどうかを検定することもできます。 糖尿病状態のグループ全体ですべての変数を比較する検定の結果を報告できます。 ただし、2 つのグループの年齢や人種構成を比較することには関心がないため、
これらのageとraceの検定は省略します。 また、「Total」というラベルの付いた列であるサンプル全体の記述統計量を非表示にします。
. dtable age weight bpsystol i.sex i.race, by(diabetes, nototals tests) continuous(age, test(none)) factor(race, test(none))
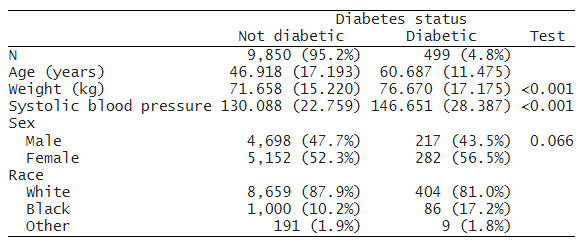
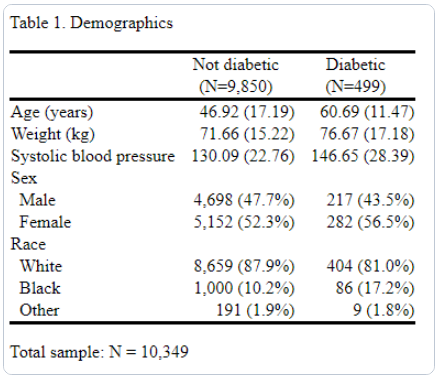
次に、サブオプション place(seplabels) を指定して、各サブサンプルの度数を列ラベルの別の行に配置します。 デフォルトでは、頻度とパーセンテージの両方がグループごとにレポートされますが、必要なのは頻度のみです。 さらに、sformat() オプションを使用して、統計の表示方法を変更できます。 ここでは、カウントを括弧で囲みます。 また、合計サンプル サイズを記載したメモを追加し、by() 変数のラベルを列ヘッダーから非表示にします。
. dtable age weight bpsystol i.sex i.race, by(diabetes, nototals tests) continuous(age, test(none)) factor(race, test(none)) sample(, statistics(freq) place(seplabels)) sformat("(N=%s)" frequency) note(Total sample: N = 10,349) column(by(hide))
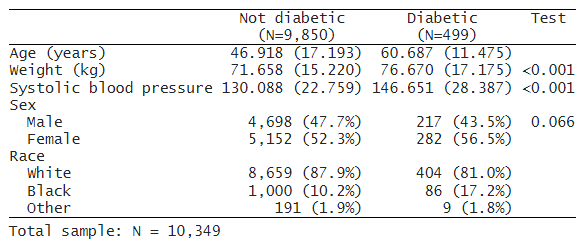
最後に、平均値と標準偏差を小数点以下 2 桁にフォーマットし、タイトルを追加して、最終的な表を HTML ファイルにエクスポートします。
. dtable age weight bpsystol i.sex i.race, by(diabetes, nototals tests) continuous(age, test(none)) factor(race, test(none)) sample(, statistics(freq) place(seplabels)) sformat("(N=%s)" frequency) note(Total sample: N = 10,349) column(by(hide)) nformat(%7.2f mean sd) title(Table 1. Demographics) export(table1.html, replace)
独自の統計量を定義する
dtable は、変動係数、幾何平均、歪度など、表に含めることができる幅広い統計を提供します。 ただし、統計を 1 つのセルに結合したい場合があります。 たとえば、四分位範囲を中央値のすぐ横に配置できます。
dtable を使用すると、サポートされている任意の統計から複合結果を作成できます。
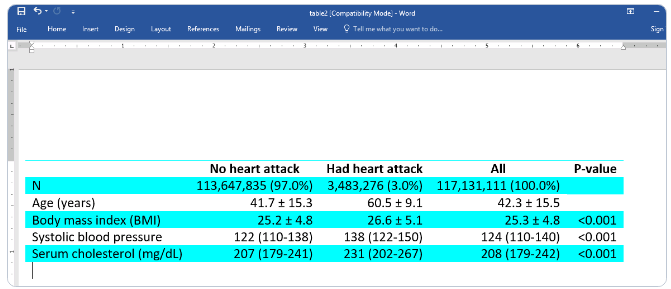
以下では、心臓発作を起こしたことのある人とそうでない人の健康関連の測定値を比較したいと思います. プラスマイナス記号で区切られた 1 つのセルに平均と標準偏差が必要です。
さらに、四分位範囲を中央値のすぐ隣に配置する必要があります。 これらの複合結果をそれぞれ定義し、区切り文字を指定します。 次に、変数ごとに必要な統計を指定します。 また、調査の重みを使用して統計が計算されるように、svy オプションを追加します。
. dtable, by(heartatk, tests) svy define(meansd = mean sd, delimiter(" ± ")) define(myiqr = p25 p75, delimiter("-")) continuous(age, stat(meansd) test(none)) continuous(bmi, stat(meansd)) continuous(bpsystol tcresult, stat(median myiqr))
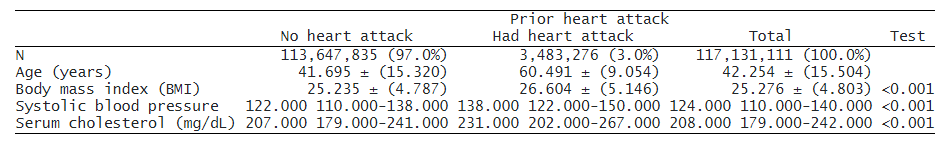
次に、パーセンタイルと中央値を小数点以下 0 桁にフォーマットし、四分位範囲を括弧で囲みます。 デフォルトでは、標準偏差は括弧内に配置されますが、以下の括弧は削除されます
. dtable, by(heartatk, tests) svy define(meansd = mean sd, delimiter(" ± ")) define(myiqr = p25 p75, delimiter("-")) continuous(age, stat(meansd) test(none)) continuous(bmi, stat(meansd)) continuous(bpsystol tcresult, stat(median myiqr)) nformat(%6.0f p25 p75 median) sformat("(%s)" myiqr) nformat(%6.1f mean sd) sformat("%s" sd)

さらに、by() 変数のラベルを削除し、「Total」列のラベルを変更し、p 値のラベルを変更します。
. dtable, by(heartatk, tests) svy define(meansd = mean sd, delimiter(" ± ")) define(myiqr = p25 p75, delimiter("-")) continuous(age, stat(meansd) test(none)) continuous(bmi, stat(meansd)) continuous(bpsystol tcresult, stat(median myiqr)) nformat(%6.0f p25 p75 median) sformat("(%s)" myiqr) nformat(%6.1f mean sd) sformat("%s" sd) column(by(hide) total(All) test(P-value))

collectコマンドを利用したカスタマイズ
dtable は 1 つのステップで表を作成してエクスポートするように設計されていますが、collect コマンド スイートを使用してこれらの表をさらにカスタマイズできます。 以下では、表の交互の行の境界線の色と背景色を変更します。
. collect style cell border_block[column-header corner], border(top, color(cyan))
. collect style cell border_block[row-header item], border(bottom, color(cyan)) border(top, color(cyan))
. collect style cell cell_type[column-header], font(, bold)
. collect style cell var[_N bmi tcresult], shading(background(cyan))
最後に、列の幅を表の内容に合わせてサイズ変更し、表をエクスポートするように指定します。
. collect style putdocx, layout(autofitcontents)
. collect export table2.docx, replace
出力されるドキュメントは次のとおりです。