混合データサンプリング(mixed data sampling: MIDAS)回帰は、異なる頻度でサンプリングされたデータを同じ回帰モデルで使用できるようにする推定手法です。MIDAS-GARCHモデルのアプローチは、低頻度系列の多数のラグから得られる情報をARCH回帰の分散式に組み込むというものです。たとえば、四半期データのラグを月次データのGARCHモデルに組み込みます。
MIDAS推定についてはこちらをご覧ください。
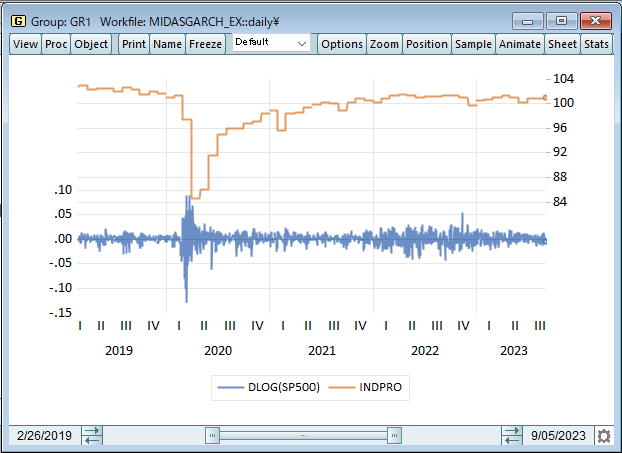

equationを入力します。Methodドロップダウンメニューで「ARCH – Autoregressive Conditional Heteroskedasticity」を選択します。あるいは、コマンドウィンドウにキーワードarchを入力すると、新しいモデルオブジェクトが作成され、推定方法が自動的に設定されます。
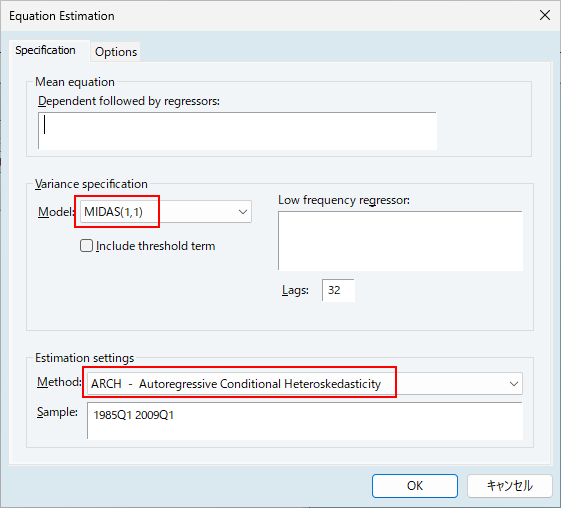
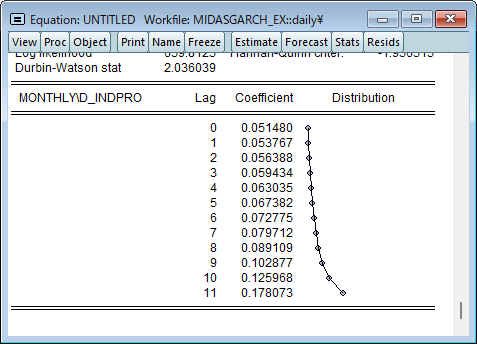
pagename\seriesnameです。ここで、pagenameは系列を含むページの名前、seriesnameは系列の名前です。Lags編集フィールドを使用して、長期コンポーネントに含める低頻度回帰変数のラグ数を指定してください。
return c、Low frequency regressorsにmonthly\d_indproを入力します。
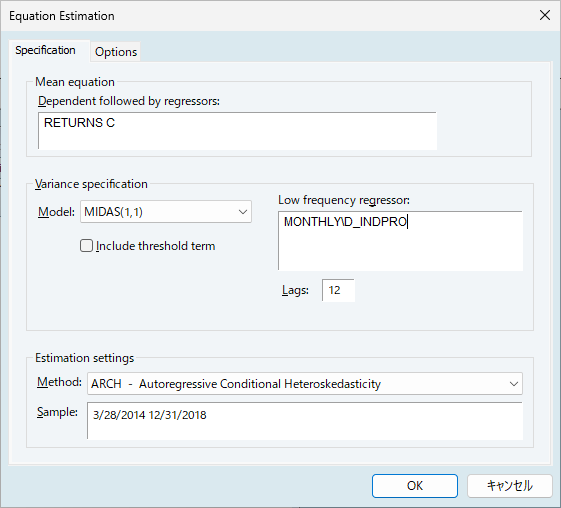
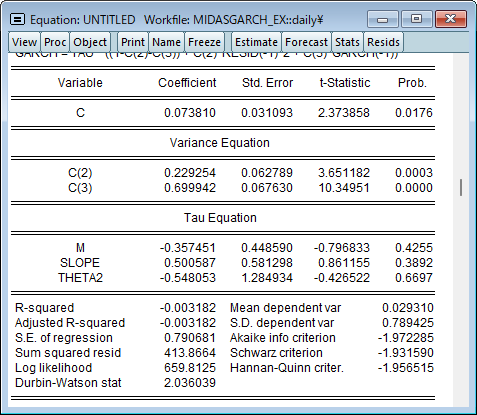
equation ex1.arch(midas) returns c @monthly\d_indpro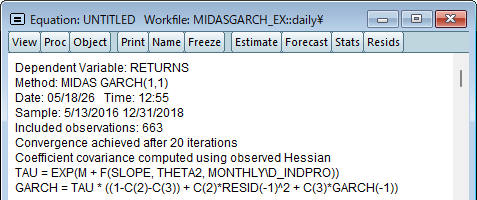

ISO27001(ISMS)認証
情報セキュリティ・マネジメントシステム

© 2026 Lightstone Corp. All Rights Reserved
