


ISO27001(ISMS)認証
情報セキュリティ・マネジメントシステム

© 2026 Lightstone Corp. All Rights Reserved
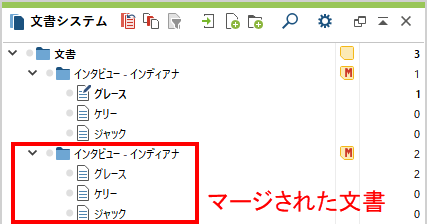

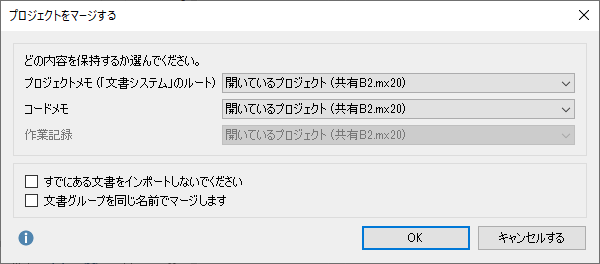
関連ページコードシステムのエクスポートとインポート
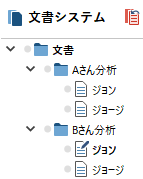

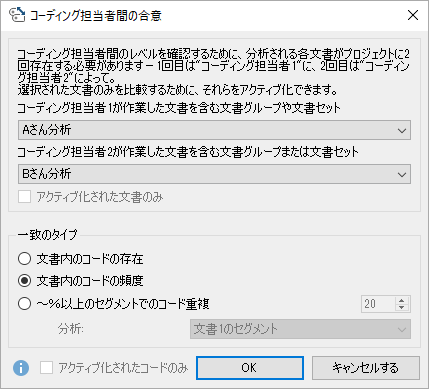

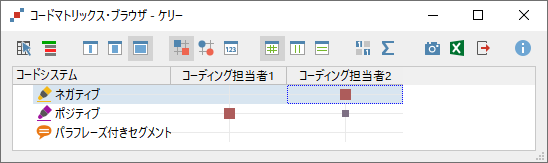
関連ページコードマトリックス・ブラウザ
「~%以上のセグメントでのコード重複」で分析し、「2つの文書ブラウザのウィンドウに表示する」を設定すると、コード付きセグメントを並べて比較することができます。
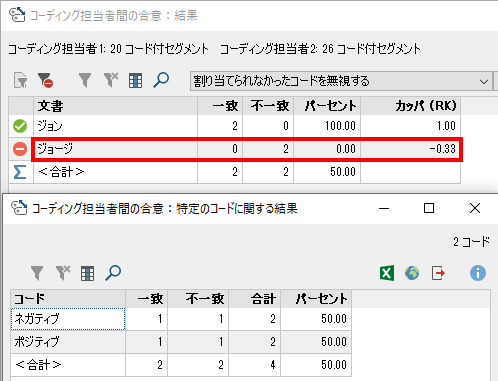
「~%以上のセグメントでのコード重複」で分析した場合は、 カッパをクリックするとΚ係数が表示されます。
カッパをクリックするとΚ係数が表示されます。
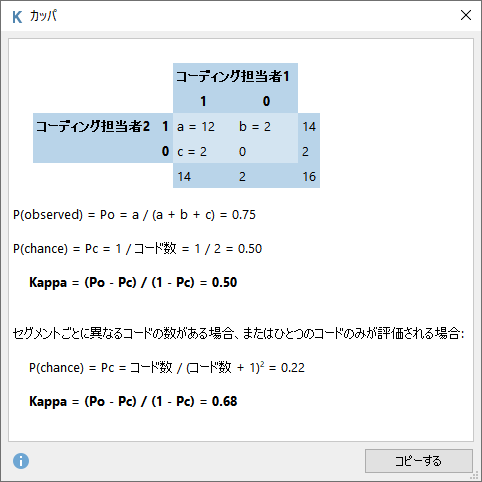
MAXQDAでは、コーディング担当者間の一致率を評価するために、Κ係数 Brennan, Prediger (1981)を計算することができます。Κ係数は、一致率から偶然による一致の影響を除外する目的で計算されます。
Landis, Koch (1977)によると、Κ係数の一致度は、下記のように判断できます。
| Κ係数 | 評価 |
|---|---|
| < 0.00 | Poor(一致しない) |
| 0.00 - 0.02 | Slight(あまり一致しない) |
| 0.21 - 0.40 | Fair(どちらでもない) |
| 0.41 - 0.60 | Moderate(そこそこ一致する) |
| 0.61 - 0.80 | Substantial(よく一致する) |
| 0.81- 1.00 | Almost Perfect(ほぼ完全に一致する) |
Κ係数のような計算を行うには、事前にセグメントの区切りと使用するコードを定義しておく必要があります。しかし、質的データ分析では、それぞれの分析者が文書全体を読み、任意のセグメントにコードを割り当てるという手順で分析を行います。この場合、二人の分析者が全く同じセグメントに同じコードを付与する確率は低くなります。
通常、一致率から偶然の一致を除いたΚ係数は、一致率に比べて一致度が低くなります。しかし、質的データ分析では偶然による一致の影響が小さいため、Κ係数は一致率とほぼ同程度になるとも考えられます。
どのような場合でも、計算結果を慎重に検討する必要があります。
ISO27001(ISMS)認証
情報セキュリティ・マネジメントシステム
© 2026 Lightstone Corp. All Rights Reserved