
記述統計
Originには、平均値や標準偏差、相関係数などデータの基本的な特徴を計算するために以下の機能を使用できます。一部機能は、Pro版でのみ利用できます。
相関係数(Pro)
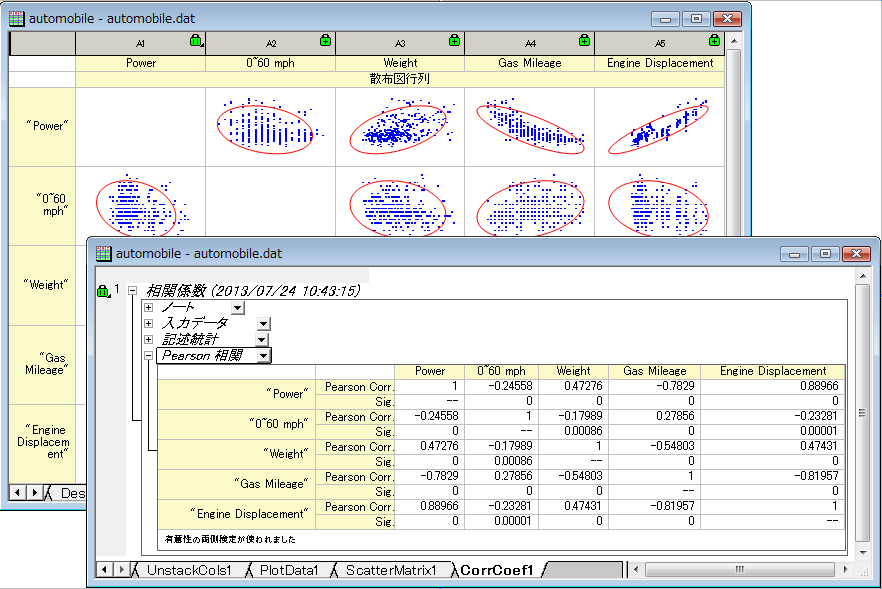 相関係数(または相互相関係数)は、2つの変数間の関係の強さを示す係数です。OriginProでは、以下3つの手法による相関係数の算出をサポートしています。
相関係数(または相互相関係数)は、2つの変数間の関係の強さを示す係数です。OriginProでは、以下3つの手法による相関係数の算出をサポートしています。
- ピアソンの積率相関係数
- スピアマンの順位相関係数
- ケンドールの相関係数
相関係数の出力オプションで、散布図行列を作図することも可能です。
列の統計/行の統計
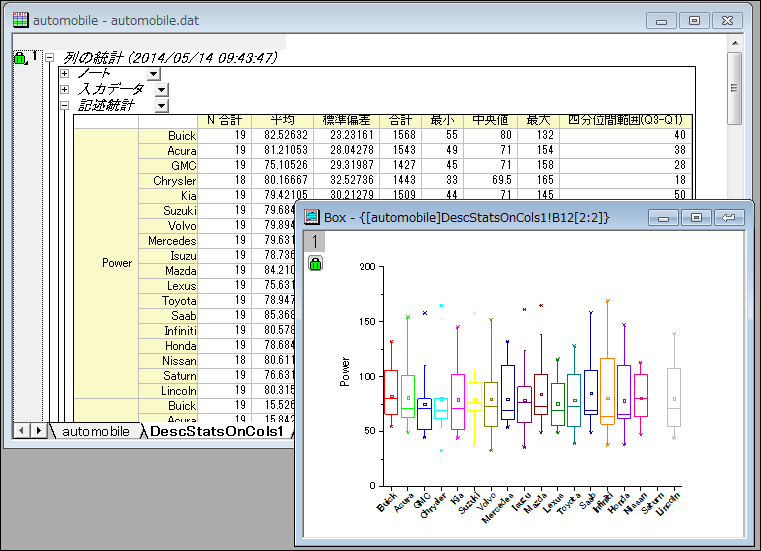 列または行方向のデータに対し、平均値や標準偏差、四分位範囲といった基本統計量を取得するための機能です。
列または行方向のデータに対し、平均値や標準偏差、四分位範囲といった基本統計量を取得するための機能です。
結果レポートには、ボックスチャートやヒストグラムといったグラフを出力することもできます。
離散度数(Pro)
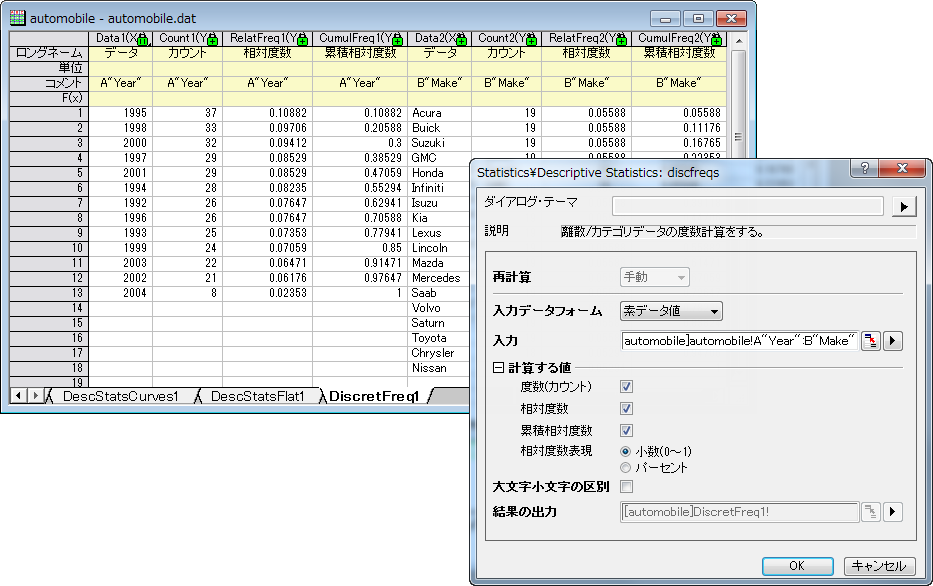 離散度数は記述統計の一般的な手法で、離散した変数を分析する際に使用します。離散度数分析の機能は度数表を出力し、その表の中からデータのサマリーを簡単かつ直感的に入手できます。
離散度数は記述統計の一般的な手法で、離散した変数を分析する際に使用します。離散度数分析の機能は度数表を出力し、その表の中からデータのサマリーを簡単かつ直感的に入手できます。
- 計算する値
- カウント:各離散データの数をカウント
- 相対度数:各離散データの相対度数
- 累積相対度数:各離散データの累積相対度数
- 相対度数表現:相対度数の表示をパーセントにするか小数にするか選択
- 大文字小文字の区別:
度数をカウントする際に、変数の大文字と小文字を区別するかどうかを指定します。
度数カウント
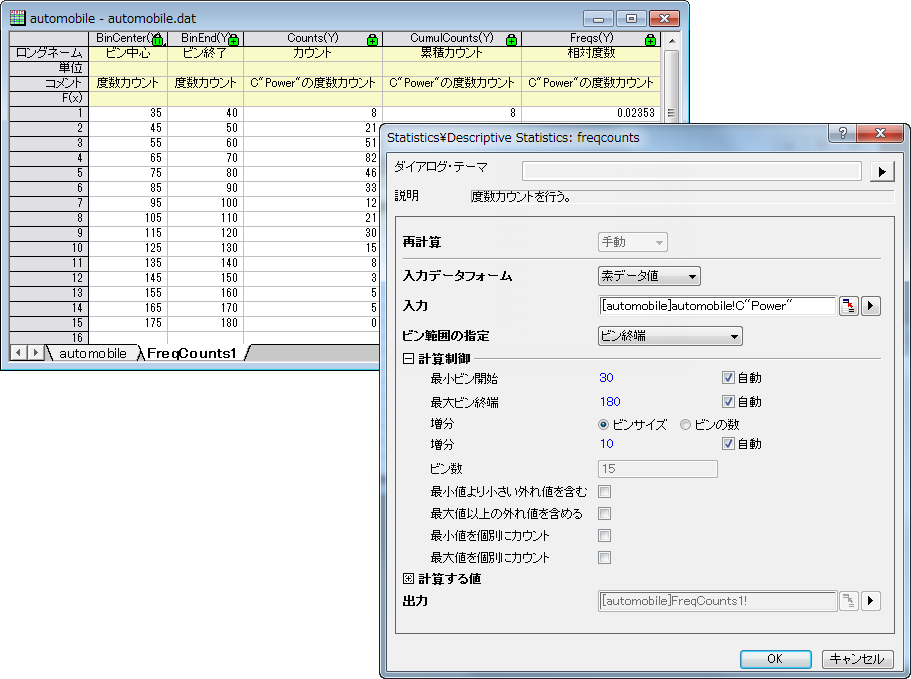 ビンサイズ(階級の間隔)やビンの数(階級数)を設定し、各階級の度数をカウントします。度数カウントの機能では、選択したデータのビンの中心、ビンの終点、度数カウント、累積カウント、相対度数、累積相対度数を出力できます。
ビンサイズ(階級の間隔)やビンの数(階級数)を設定し、各階級の度数をカウントします。度数カウントの機能では、選択したデータのビンの中心、ビンの終点、度数カウント、累積カウント、相対度数、累積相対度数を出力できます。
正規性の検定
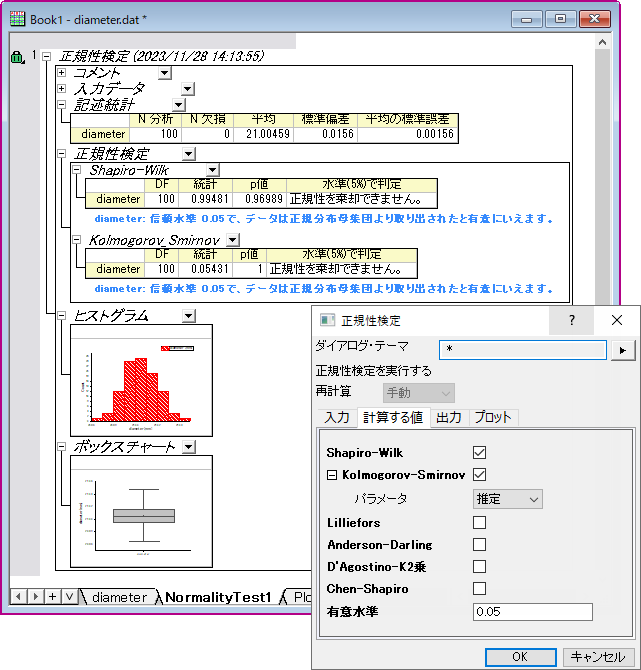 正規性の検定は、入力データの母集団が正規分布に従うかどうかを検定します。t検定や分散分析などデータが正規分布に従うことを仮定する統計手法を使う場合に便利です。
正規性の検定は、入力データの母集団が正規分布に従うかどうかを検定します。t検定や分散分析などデータが正規分布に従うことを仮定する統計手法を使う場合に便利です。
Originでは以下の手法で正規性の検定を実行することができ、サンプルサイズや平均値、標準偏差といった記述統計値とともに統計量やP値などの検定結果が出力されます。
- Shapiro-Wilk
- Kolmogorov-Smirnov ※
- Lilliefors
- Anderson-Darling
- D'Agostino-K二乗(歪度、尖度、オムニバス)
- Chen-Shapiro
※Kolmogorov-Smirnovを選択すると、統計値を算出する際の2つのオプションを指定できます。一つが「推定」でサンプルデータから推定される平均と分散を使用します。もう一方が「指定」で、ユーザが指定した平均と分散の値を使用して計算を実行します。
入力データのグループ分けや、結果シートにボックスチャートやヒストグラムを出力するオプションも利用できます。
2D度数カウント/ビン化
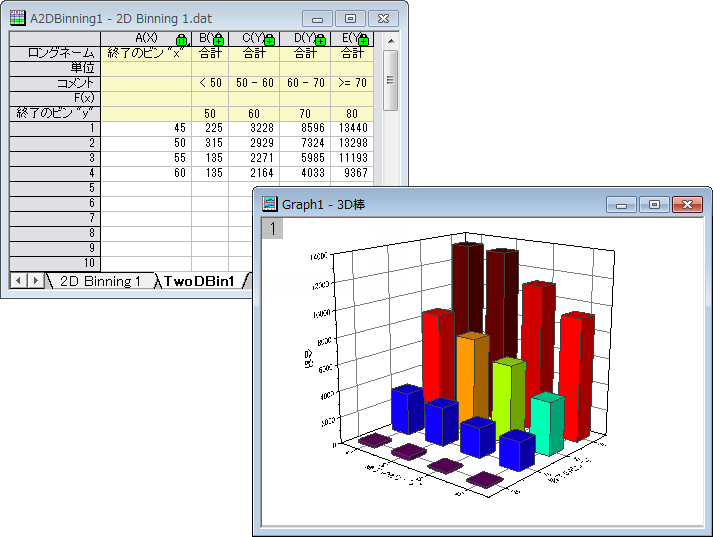 2つの変数を持つデータの度数をカウントします。必要に応じて、結果の3D棒グラフやイメージプロットを作図できるので、データポイントの分布を視覚的に表現できます。
2つの変数を持つデータの度数をカウントします。必要に応じて、結果の3D棒グラフやイメージプロットを作図できるので、データポイントの分布を視覚的に表現できます。

