

ISO27001(ISMS)認証
情報セキュリティ・マネジメントシステム

© 2026 Lightstone Corp. All Rights Reserved
Originでピークアナライザを使ってピーク分離を行う際にはピーク検索をしてピークのだいたいの位置や、ピークの個数を決定してからピークフィットを実行する必要があります。しかし、自動検索では必要なピークが検索されない、検索されるピーク個数が多すぎるなどデータによってはピーク位置を検索することが難しい場合があります。今回は検索設定のヒントになるよう、あるデータに対していくつかの手法でピーク検索を試して各手法の特徴を解説いたします。
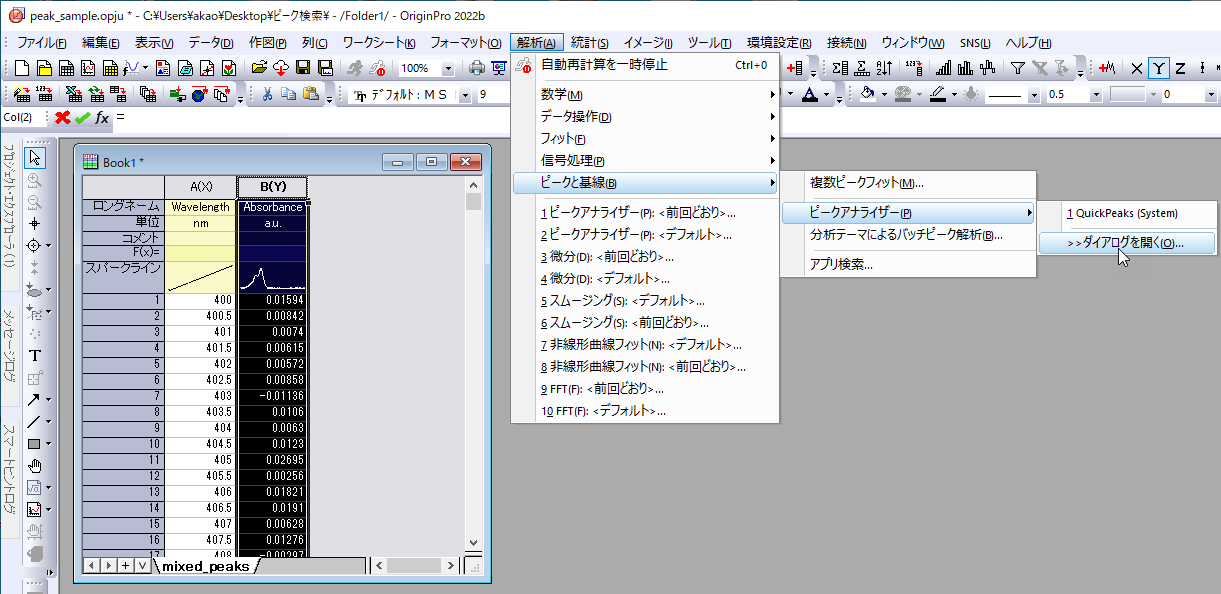
Originでピーク検索、ピークフィットを行う場合にはピークアナライザが便利です。まずはサンプルデータを選択してメニューの 解析:ピークと基線:ピークアナライザ を選択してピークアナライザを起動します。
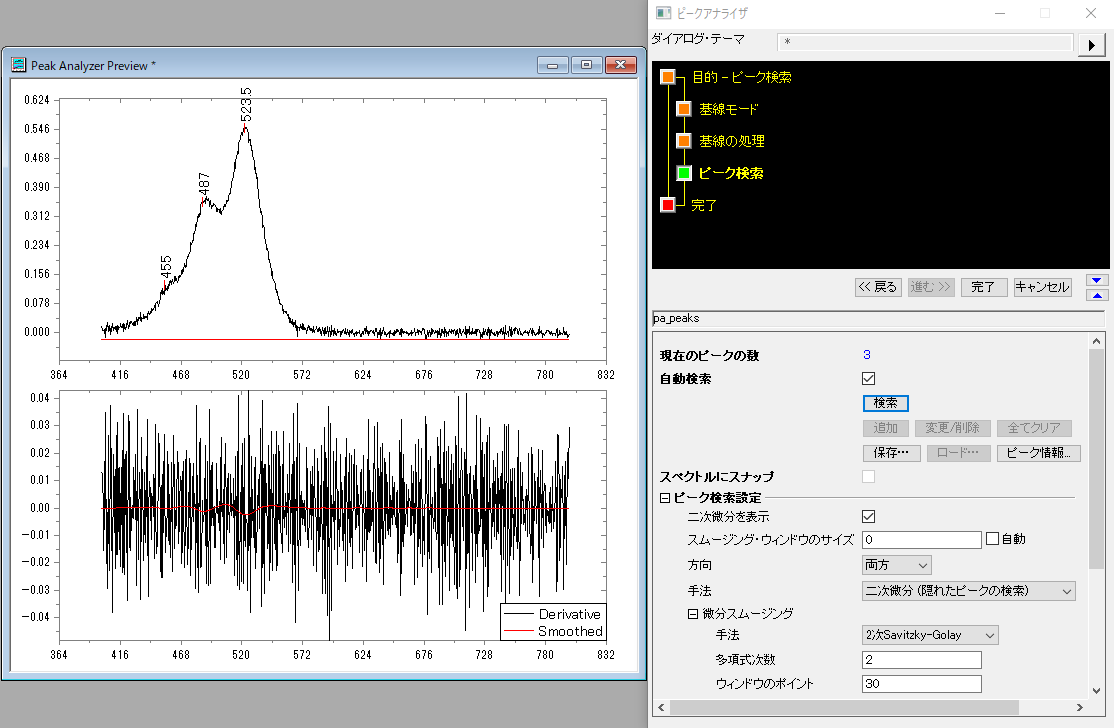
ピークアナライザを起動すると2つのウィンドウが開きます。1つがピークアナライザ本体のウィンドウ、もう一つが"Peak Analyzer Preview"というウィンドウです。設定はピークアナライザ本体のウィンドウで行っていきますが、手順を進めていくと"Peak Analyzer preview"のウィンドウにどんどん設定した情報が追加されていきます。つまり、設定したものをグラフ上で確認しながら進めていくことができます。
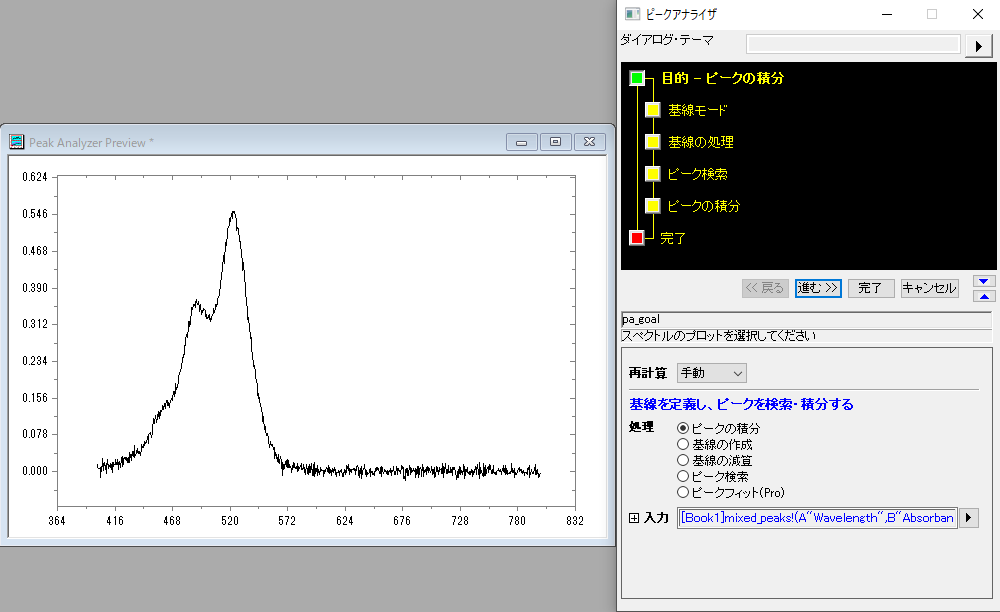
今回はピーク検索を行いますので、ピークアナライザのウィンドウで「ピーク検索」を選択して「進む>>」で進めていきます。
進めると最初は基線モードに手順が移ります。今回はデフォルトのまま「進む>>」で次に進みます。
進めると設定した基線を使った減算などの処理を行う手順が表示されますが、こちらもデフォルトのまま進めていきます。
基線の設定について各項目について詳しく知りたい場合はOrigin開発元のヘルプページをご覧ください。
※右上のドロップダウンリストから「日本語」に変更できます。
次に進むとピークを検索する手順に移ります。ここからピーク検索の各方法についてこのデータに対して検索を行いながら解説します。
ピーク検索の設定を見るとデフォルトで「自動検索」にチェックが入っています。この状態で「検索」ボタンをクリックすればデフォルトの手法・設定で検索が行われます。試しにこのまま検索してみると…
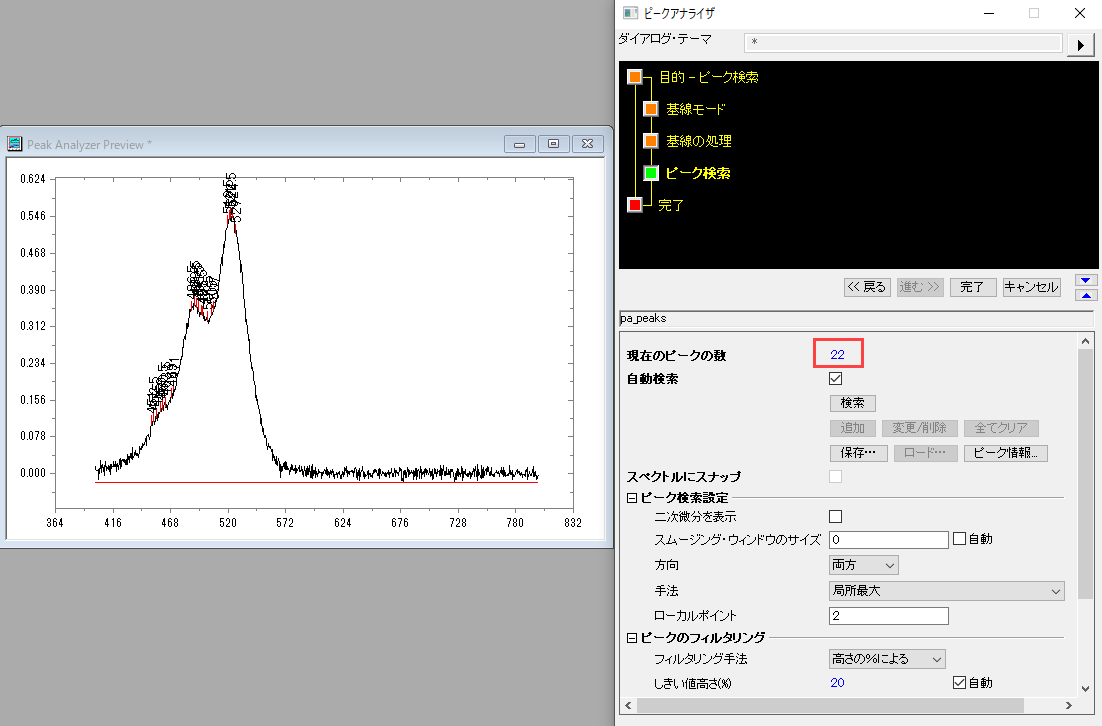
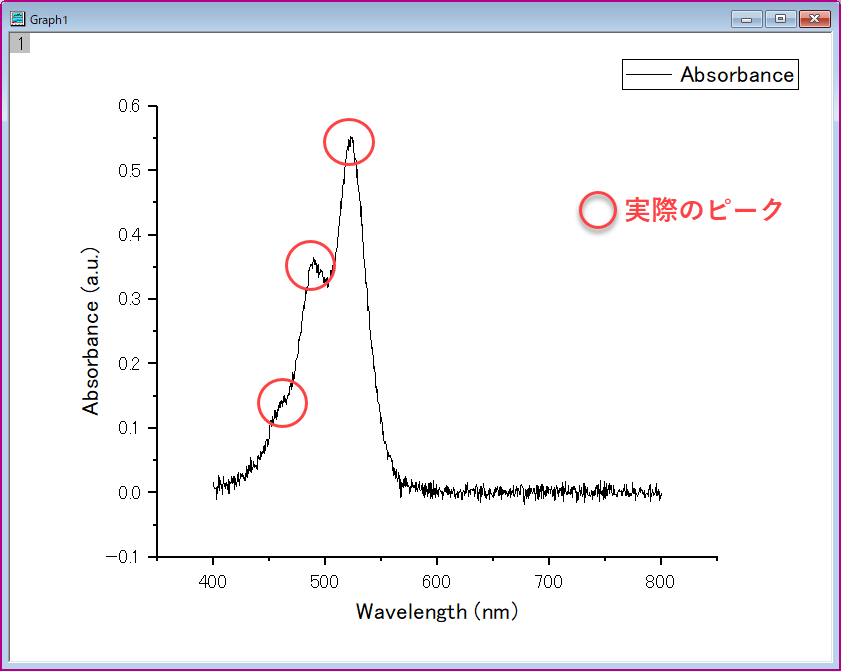
"Peak Analyzer Preview"のウィンドウ上に検索されたピーク位置が現れます。ピークが多く検出されたため、文字が重なって読めません。また、ピークアナライザのウィンドウには「現在のピーク数」のところに"22"と表示されており、ノイズもピークで拾ってしまっていることがわかります。
デフォルトの設定ではピークがうまく取れませんでしたので、設定を調整する必要があります。
ピーク検索時に設定できる項目を大きく分けると
の3つがあります。
これらを調整してサンプルデータにある3つのピークを検索してみましょう。
自動検索ではなく手動でピーク位置を設定することもできます。「自動検索」のチェックを外して「追加」ボタンをクリックすると"Peak Analyzer Preview"ウィンドウ上でダブルクリックして1点ずつ、ピークを追加することができます。
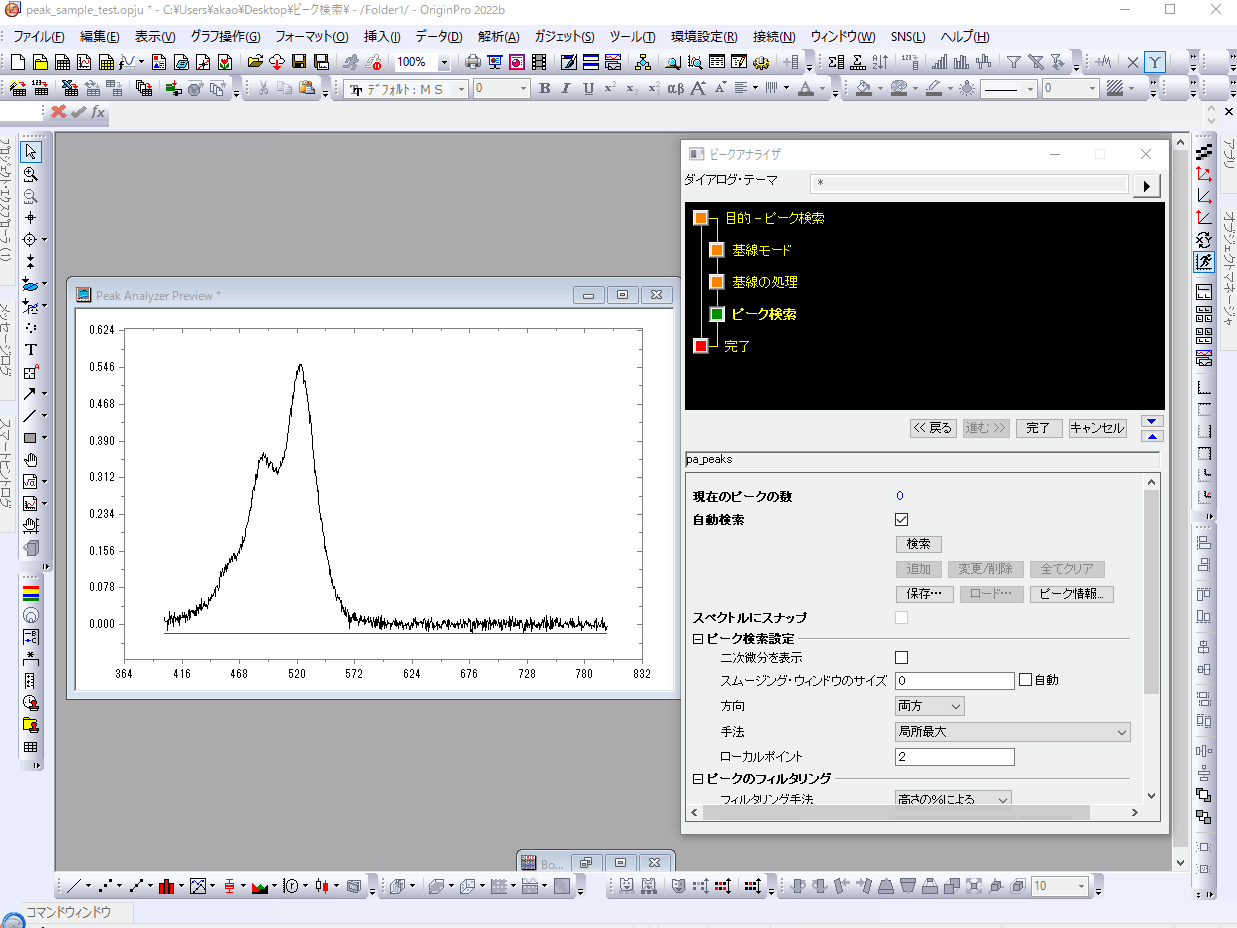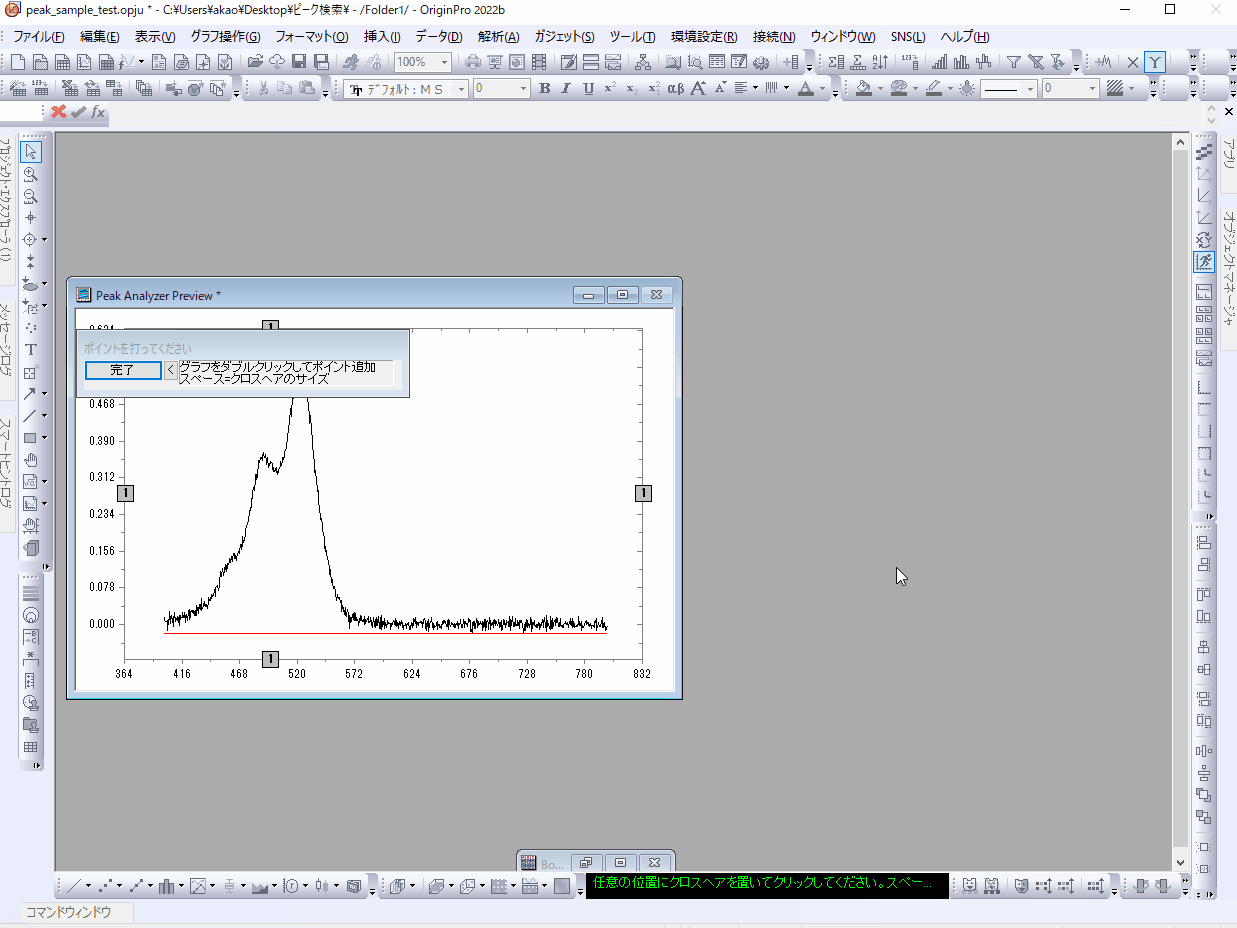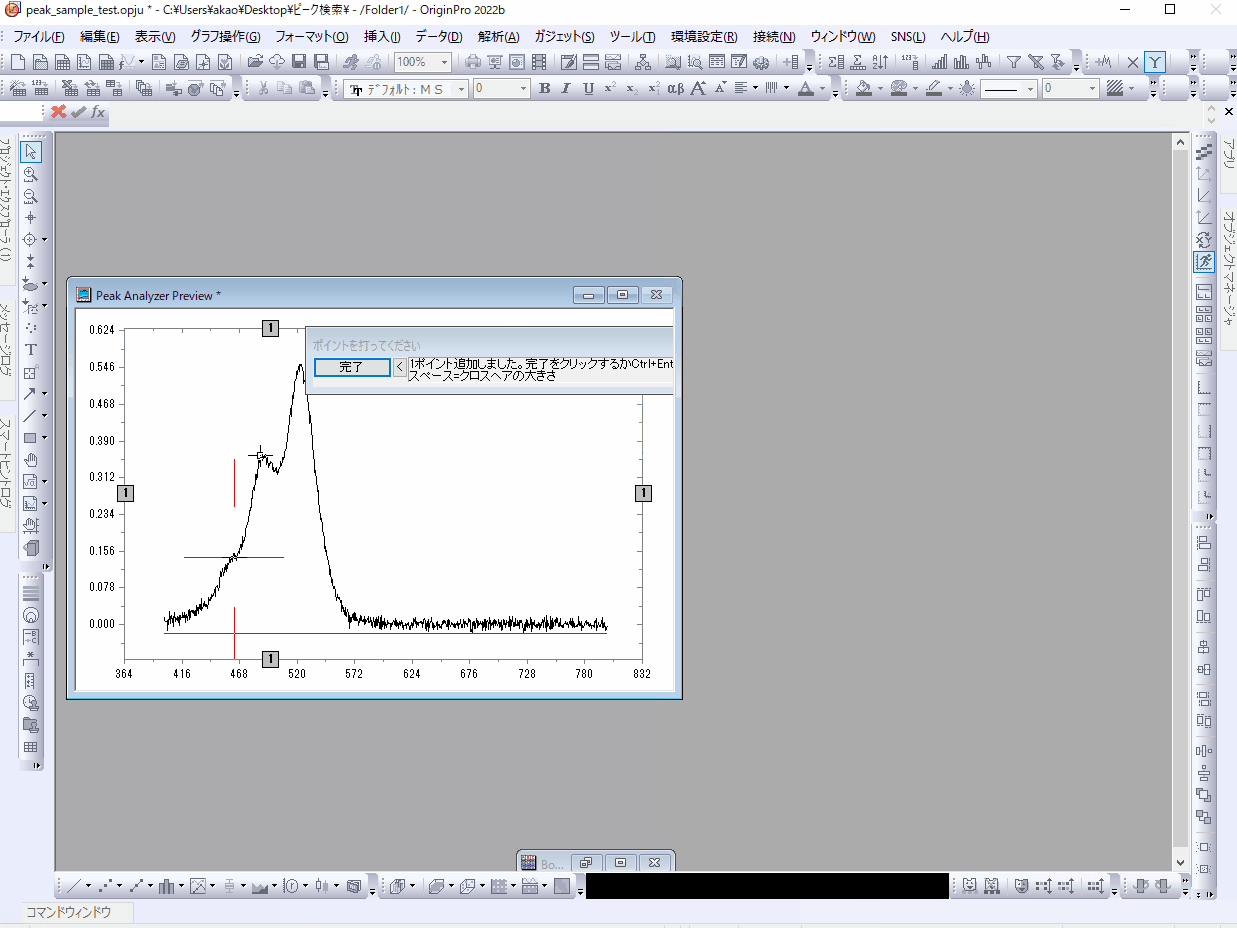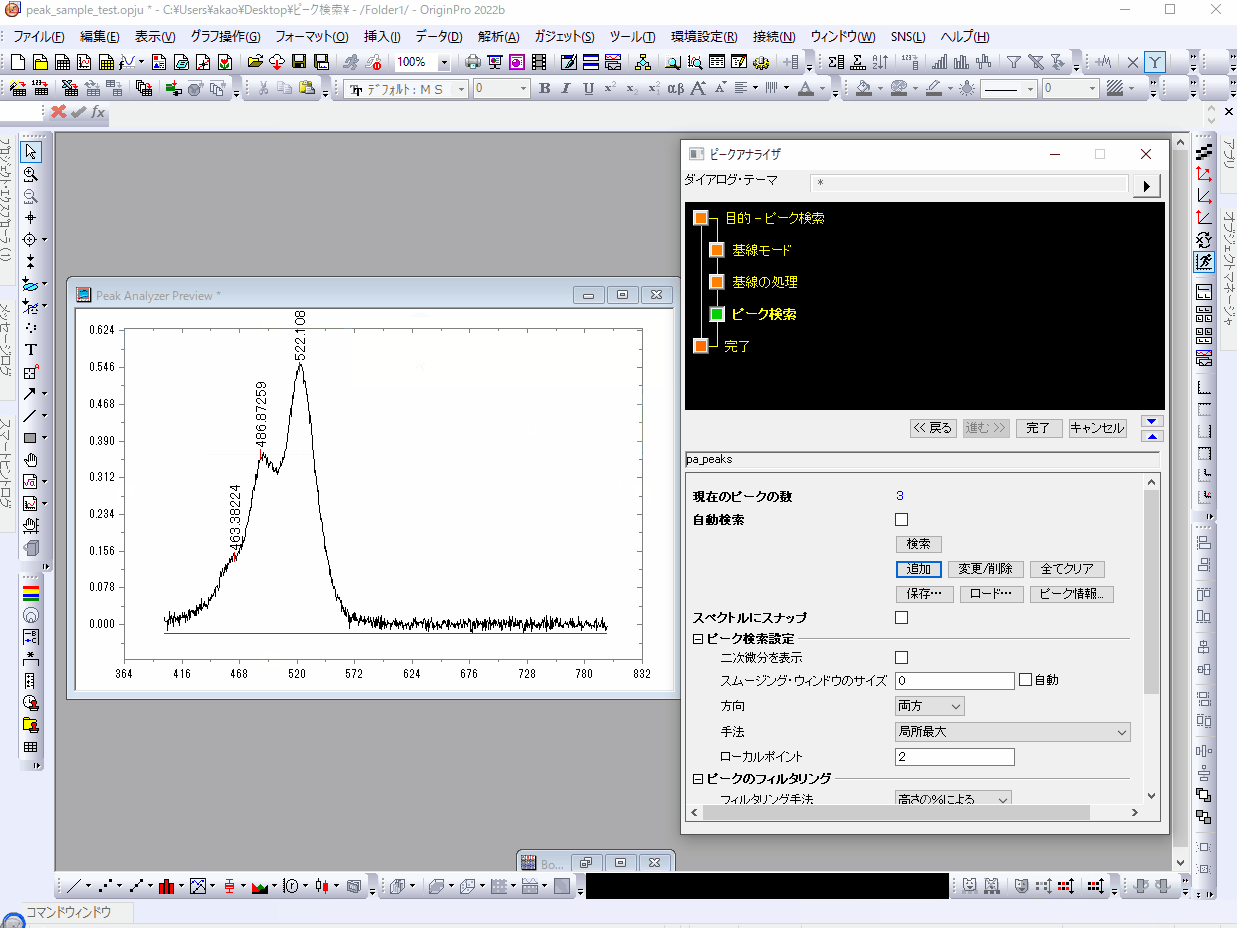
上記で挙げた3つのうち、大きく検索結果に影響してくるのが「ピーク検索手法」です。ピークアナライザ上でいうと「ピーク検索設定」内の「手法」にあたります。ここを変更することで検索のされ方が大きく変わります。
デフォルトで設定されている(さきほど使用した)手法は「局所最大」です。
局所最大ではある点がローカルポイントで指定したぶんの隣り合う点と比較して極値になっているかどうかを調べ、極値になっていればピークとして検出する方法です。ローカルポイントで前後何点を比較するかを指定できます。ローカルポイントを"2"に設定すると中心のポイント1点と前後2点、つまり計5点を比較して中心が極値になっているかどうかを見ます。
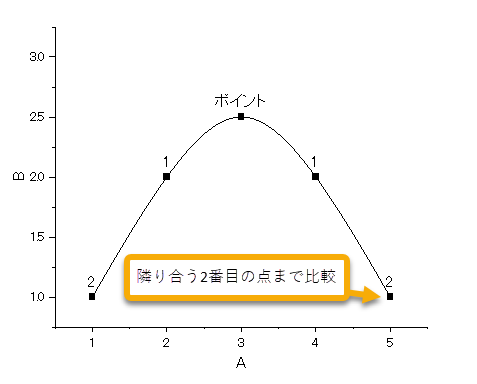
局所最大の場合、ノイズが多く入っているデータではローカルポイントが小さい値だとノイズをピークとして拾ってしまうことがあります。また、ピークが重なっている(隠れたピークがある)場合には下図のようにうまく検出されないことがよくあります。
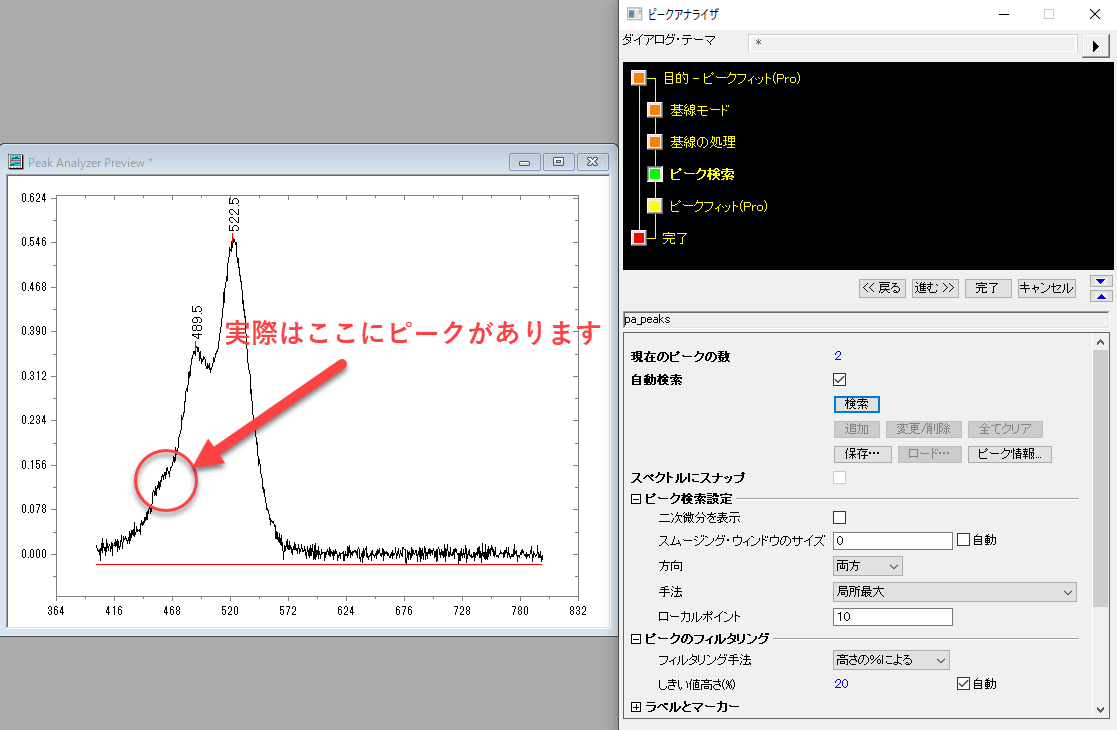
今回のデータに対してはローカルポイントの値を変えてもうまく3つのピークだけが検索されません。
では次に「ウィンドウサーチ」という手法に変えて検索してみます。手法だけ変更してそのまま再度「検索」ボタンをクリックします。これで新たに設定した手法でピークが再検索されます。
ウィンドウサーチは局所最大に似た手法です。ウィンドウサーチではウィンドウの幅や高さを指定してウィンドウサイズを決めてそのウィンドウにピークがあるかを検索します。局所最大に似た手法のため、同様にピークが重なっている場合にはうまく検出されないことがよくあります。ウィンドウサーチでは局所最大とは異なり、ウィンドウの幅に加えて、高さを指定することができます。
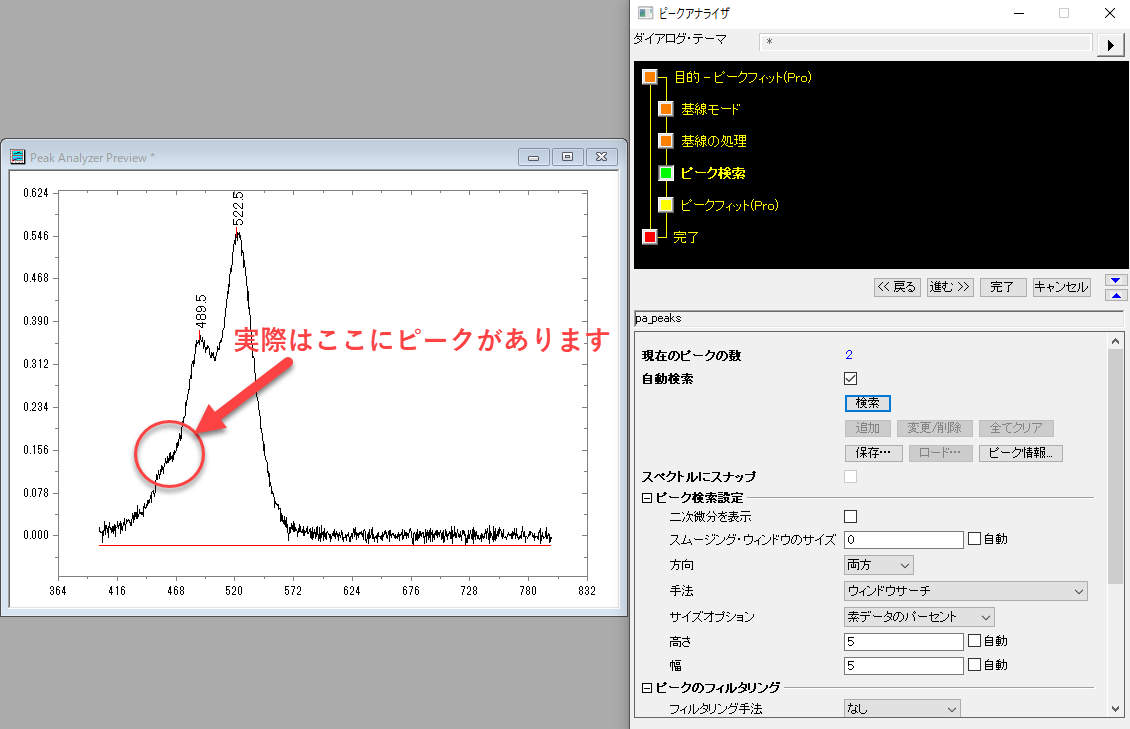
今回のデータにウィンドウサーチでピークを検索するとデフォルトでは1つしかピークが検索されません。ウィンドウサーチでは高さと幅を設定することができますので、「高さ」と「幅」の項目にある「自動」のチェックを外して任意の値を入れて検索しなおしてみますが、なかなかピークが2つ以上検索される条件というのがありません。「高さ」「幅」を"5"にすると2つピークが検出されますが、条件を探すのも一苦労です。
ではまた別の手法でやってみましょう。今度は「一次微分」に設定して検索してみます。
元データを一次微分した結果をもとにピークを検索します。一次微分の値が正から負に変化するところをピークとして検出します。そのため、ノイズが多く入っているデータでは下図のようにノイズがそのままピークとして出てしまうことがよくあります。
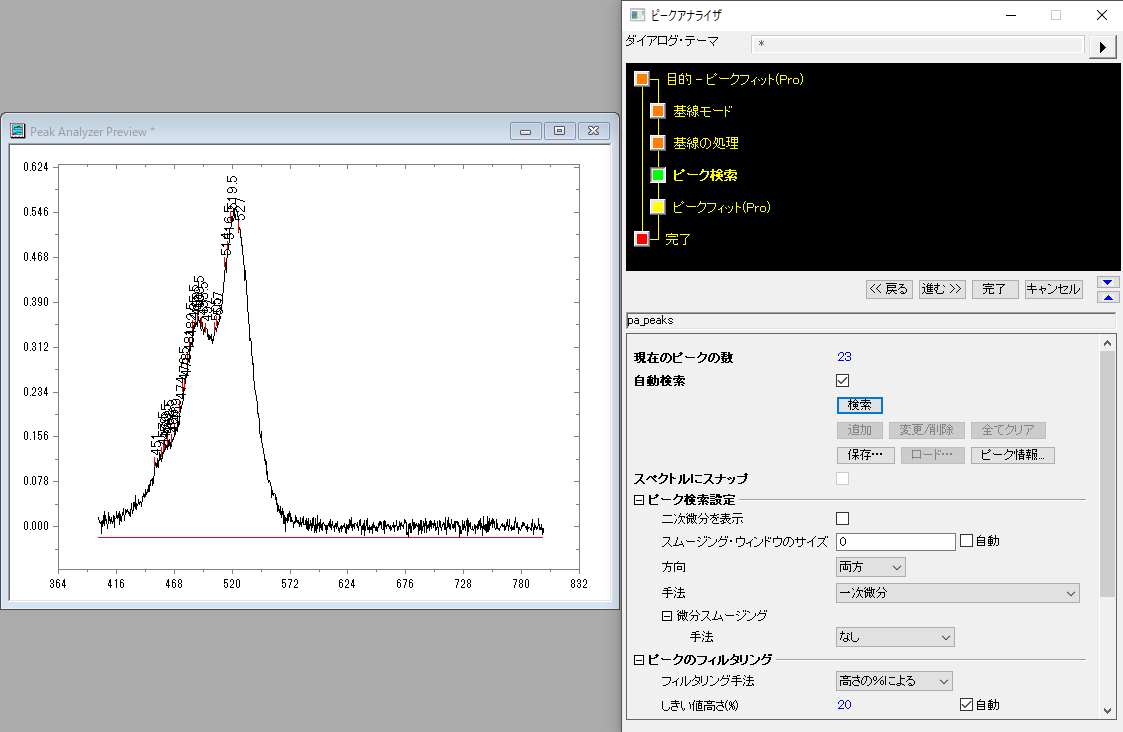
今回のデータに対して一次微分を使うと多くの点がピークとして検索されてしまいます。
次は「二次微分」で検索してみます。
元データを二次微分した結果をもとにピークを検索します。二次微分の結果の値で負の方向に凸になっているところをピークとして検出します。重なっているピークを検出する場合に利用します。ただ、こちらも一次微分と同様に、ノイズがピークとして検出される場合が多くあります。
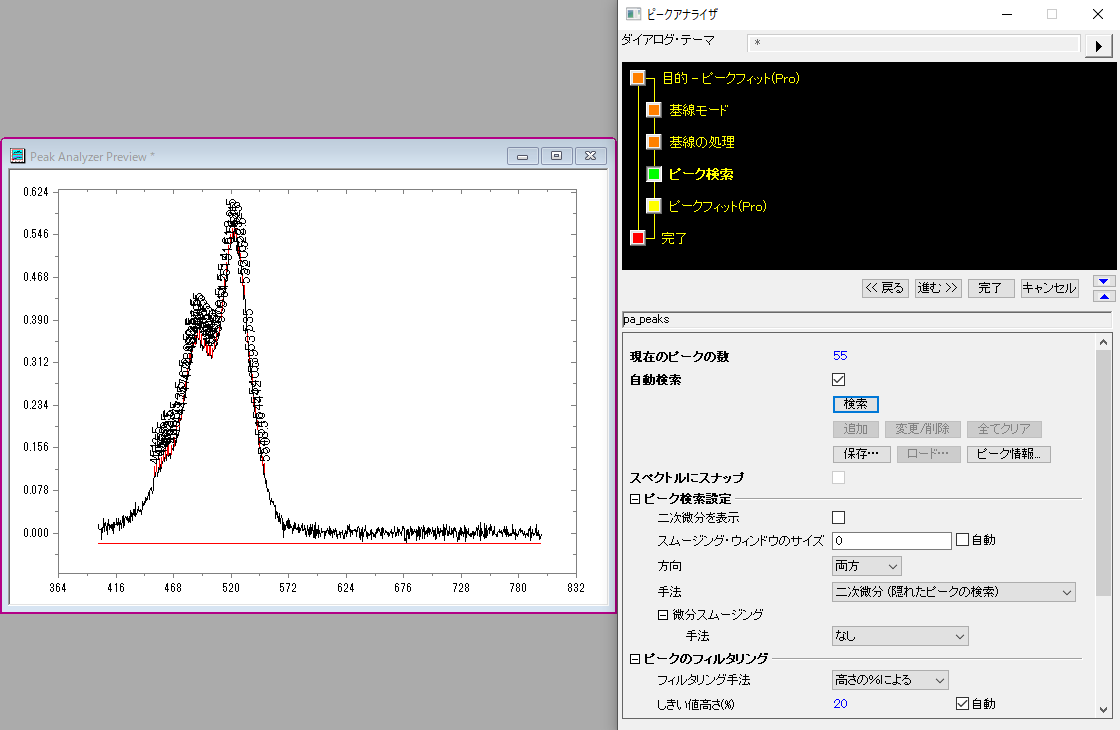
二次微分でも多くの点がピークとして検索されてしまいます。
二次微分の場合には「二次微分を表示」にチェックを入れておくことで"Peak Analyzer Preview"のウィンドウ上に元データと合わせて二次微分の結果も表示することができます。
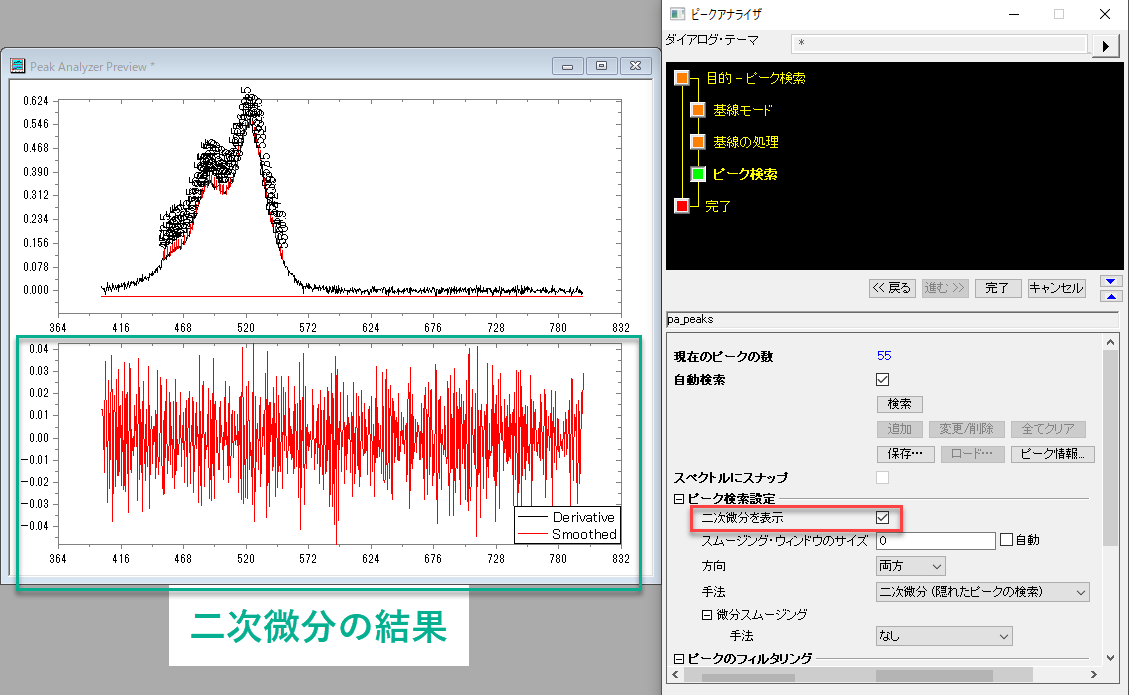
今度は「一次微分後の残差」という手法で検索してみます。
元データを一次微分した結果をもとにピークを検索します。一次微分の値が正から負に変化するところをピークとして検出します。そのため、ノイズが多く入っているデータでは下図のようにノイズがそのままピークとして出てしまうことがよくあります。
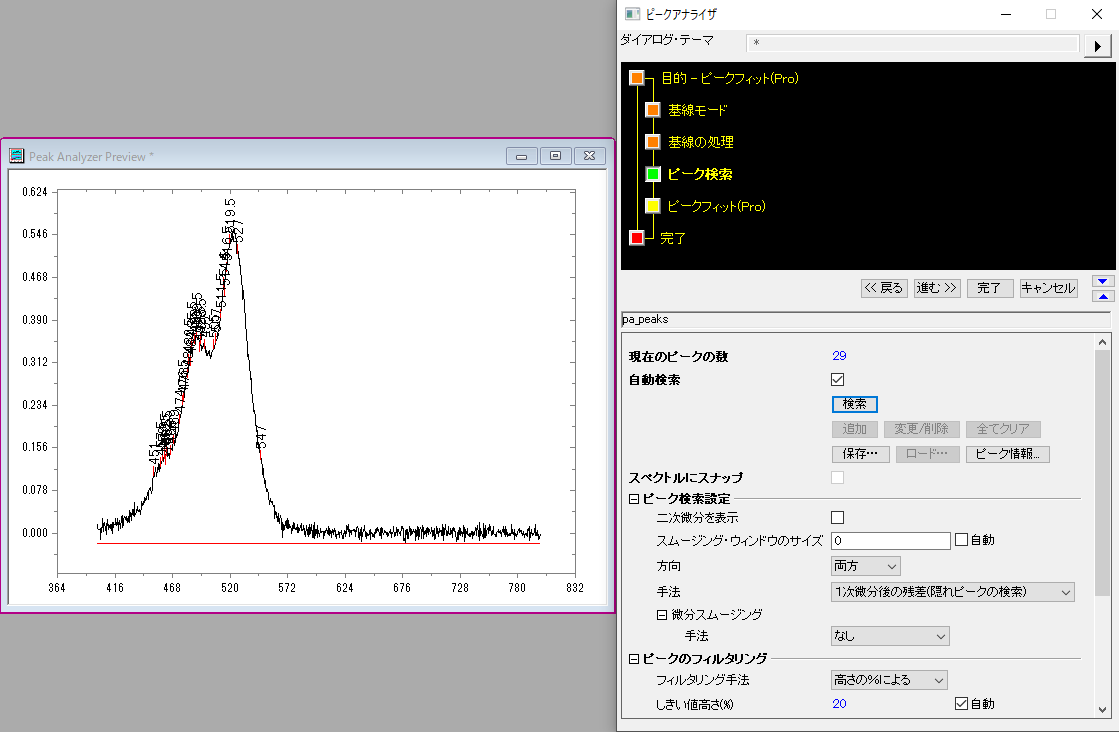
最後の「フーリエセルフデコンボリューション」で検索してみます。
フーリセセルデコンボリューション(FSD)はスペクトルのオーバーラップを探す際に利用されます。FSDの結果から局所最大法でピークを検索します。
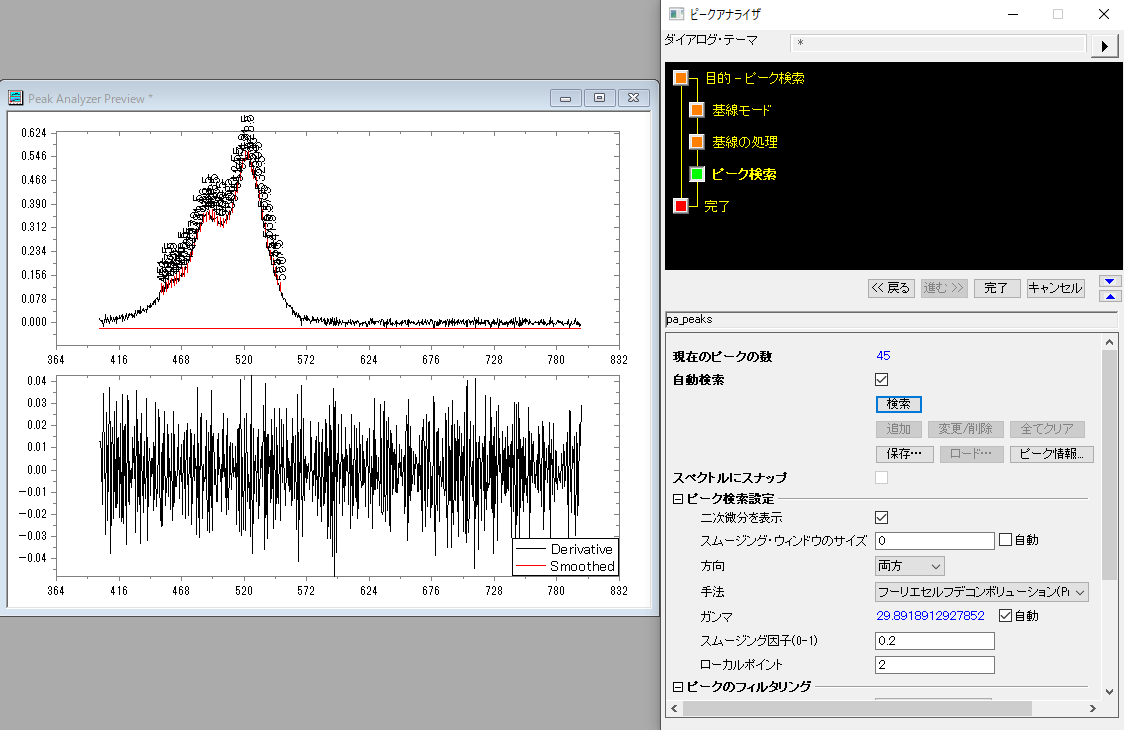
どの手法でも求めるような3つのピークを出すことは難しそうですが、これ以外にも設定できる項目がありました。それが「スムージング」です。
スムージングは元データにノイズが多い場合に特に有効です。今回のデータもノイズが多く、そのまま各手法を適用するだけでは3つのピークを検索するのは難しいため、スムージングをしてみましょう。
ピーク検索の際には「スムージングのウィンドウサイズ」に0以外の数値を入れて利用できるSavitzky-Golay法によるスムージングと、検索手法が「一次微分」「二次微分」「一次微分後の残差」の場合に利用できる微分スムージングの2種類があります。
このスムージングはSavitzky-Golay法を用いて元データをスムージングするもので、どの手法でピーク検索をする場合でも使用できます。Savitzky-Golay法では近似する多項式の次数とウィンドウのポイント数を指定することができますが、ここでは多項式の次数は"2"に固定され、ウィンドウのポイント数のみ設定できます。試しに「手法」を「局所最大」にして「スムージングのウィンドウサイズ」を「10」でスムージングすると"6"つのピークが検索されました。「スムージングのウィンドウサイズ」を少し大きくすると検索されるピークが減りますが、実際のピークの位置に3つのピークが現れるサイズはなさそうです。また、「手法」を「ウィンドウサーチ」にしても3つ検索するのは難しそうです。
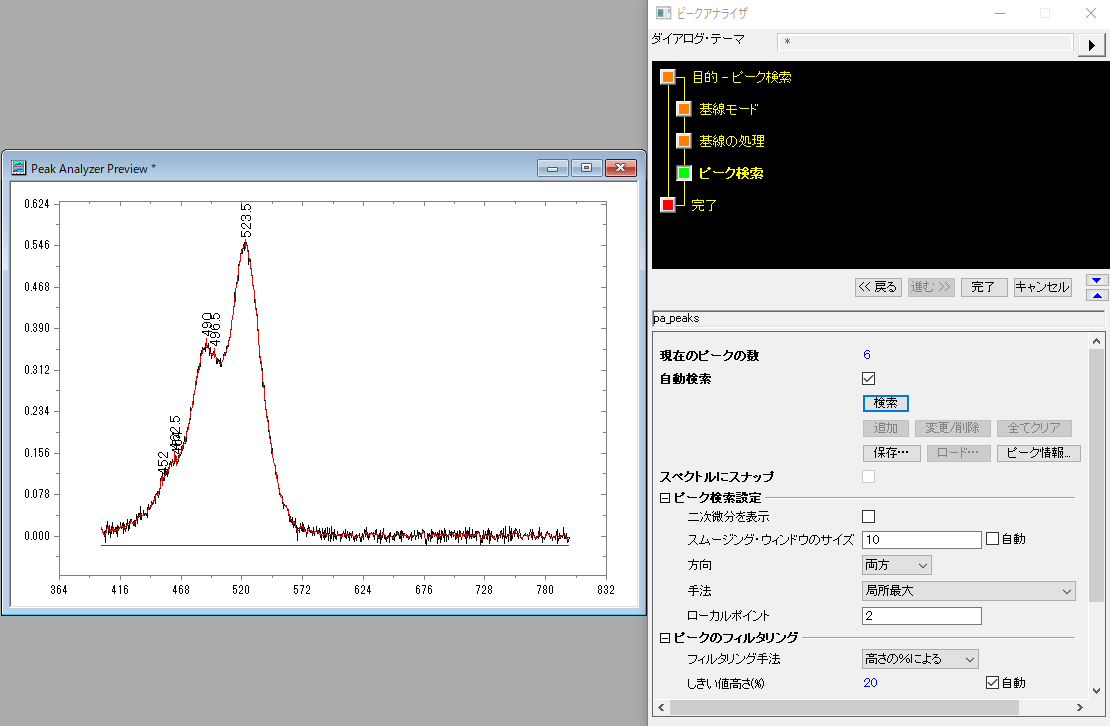
ではもう一つの「微分スムージング」をやってみます。
ピーク検索の手法が「一次微分」「二次微分」「一次微分後の残差」の場合に、元データの微分データに対してスムージングを行い、その結果を使ってピークを検出する際に使用します。元データにノイズが多い場合には元データ自体をスムージングするよりも微分スムージングを行うことで必要なピークが検出しやすくなることがあります。
微分スムージングの方法としては「一次微分」「一次微分後の残差」では「Savitzky-Golay」のみが、「二次微分」では「FFTフィルタ」「隣接平均法」「2次Savitzky-Golay」の3つを加えた4つが利用できます。
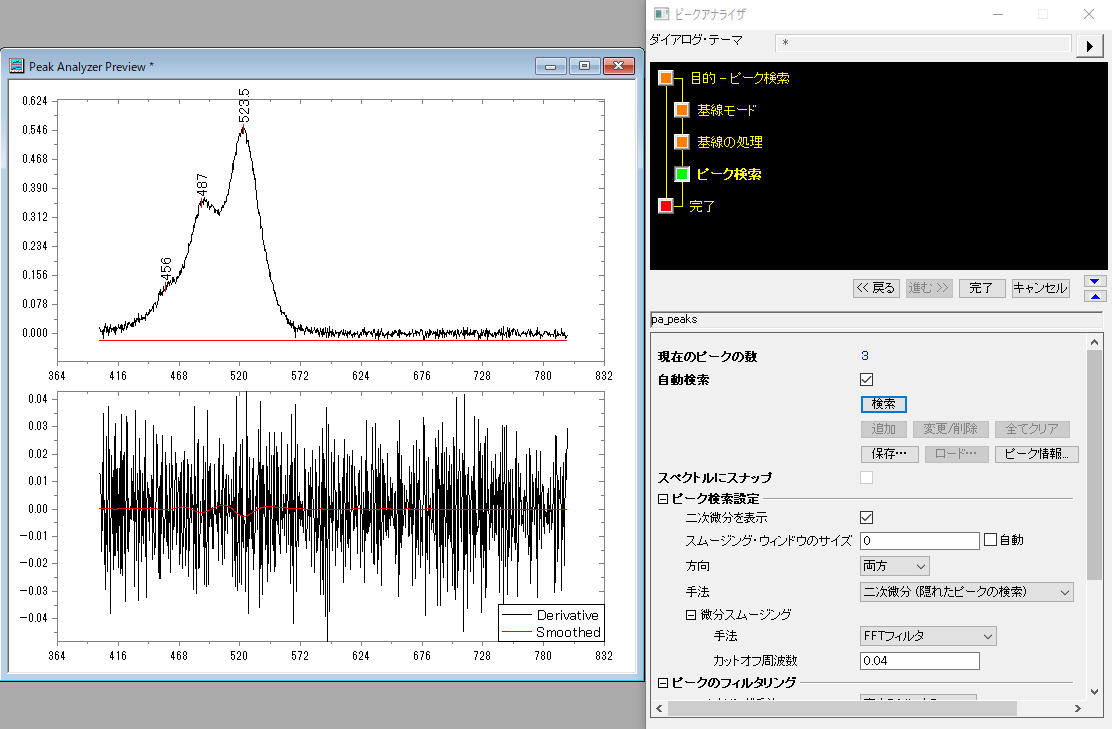
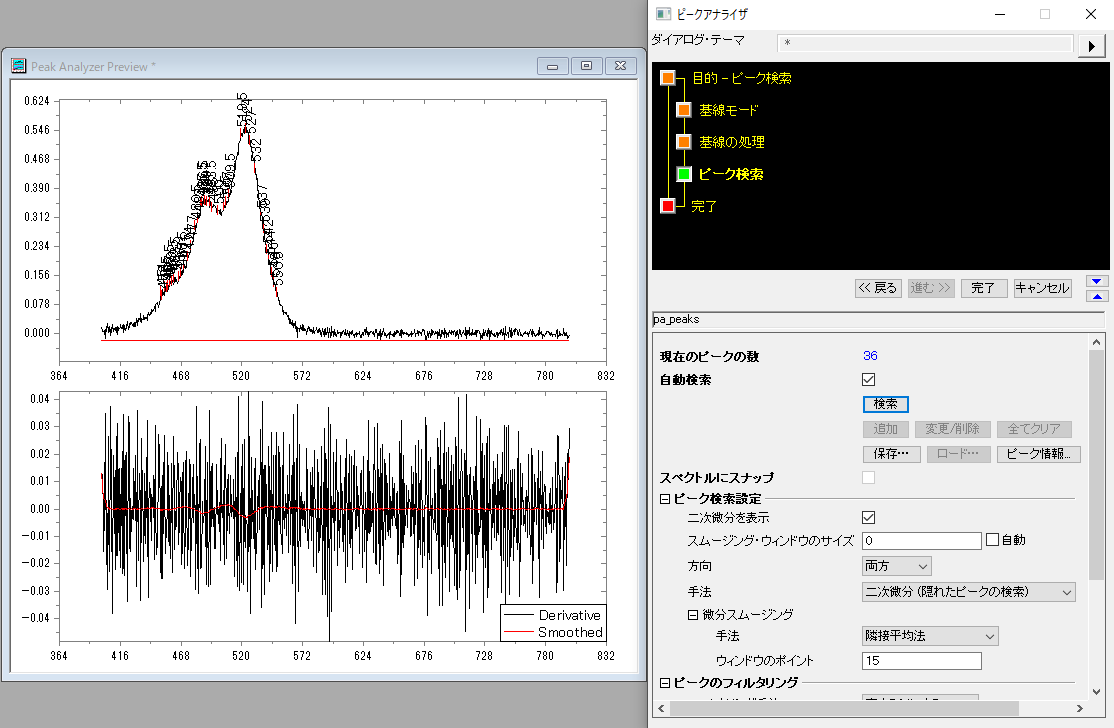
今回は「二次微分」で各スムージング方法を試してみます。
微分スムージングの各手法について
元データで高い周波数をもつ成分を除外してスムージングします。カットオフ周波数を指定することができます。
設定したウィンドウのポイント数に合わせてウィンドウを作成し、ウィンドウ内での平均を取ります。
手法としては「スムージングのウィンドウサイズ」を指定して利用できるSavitzky-Golay法によるものと同じですが、これは微分データに対して実行します。こちらはウィンドウサイズ、次数ともに設定できます。
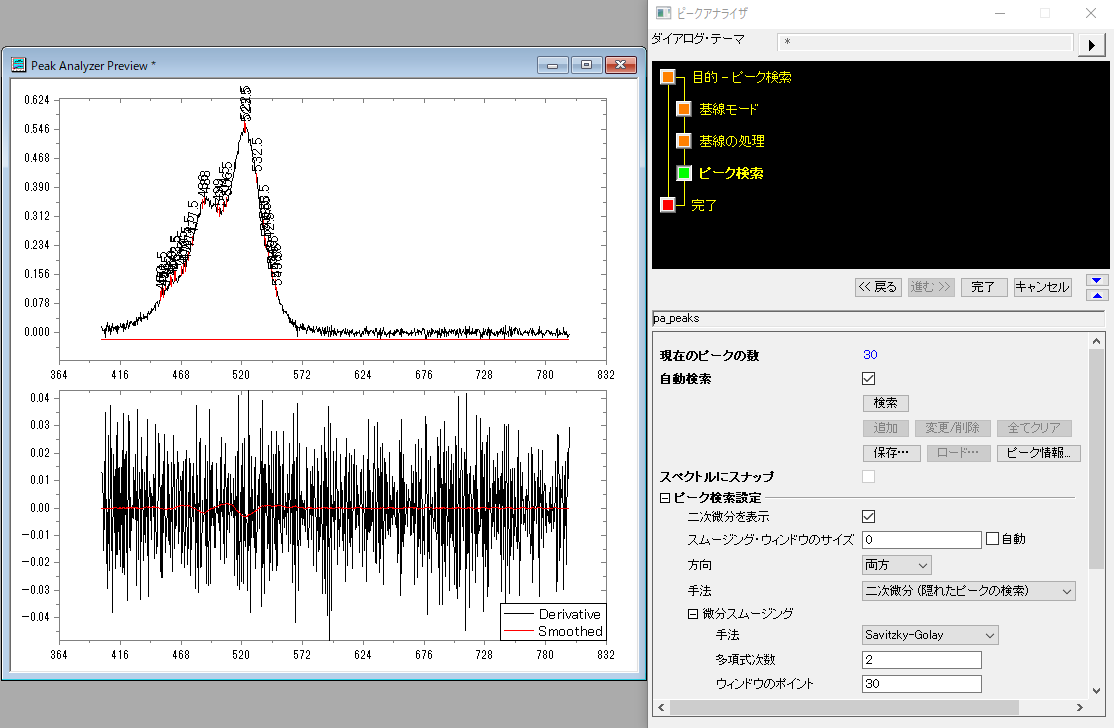
2次Savitzky-Golayでは一次微分に対してSavitzky-Golay法を実行したあとさらに微分してから再度Savitzky-Golay法を実行するものです。一般的には通常のSavitzky-Golay法と比べて2次Savitzky-Golayのほうがよい結果が得られます。
各手法で微分スムージングを使って、ピーク検索をしてみると「二次微分」で「FFTフィルタ」や「Savitzky-Golay法」を使うと3つのピークが実際のピーク位置とほぼ同じ場所で検索されます。今回の場合にはこれが適当そうです。ほかにも適当な方法があるかもしれません。
また、もう1つ検索時の設定として「ピークのフィルタリング」という項目があります。フィルタリングはピークを検出時に高さやピークの個数に制限を設けたい場合に利用します。今までのピーク検索作業でも実はフィルタリングされた状態で実行されていました。デフォルトではデフォルトで「高さの%による」の「20%」に設定されているため、フィルタリングをしたくない場合には必ず設定を「なし」に変更してピーク検索を実行してください。
設定としては「なし」以外に下記の4つがあります。
ピークの高さがデータのY座標の最大値から設定した%以下しかないものはピークとして除外します。ベースラインに近い小さなピークを除外したい場合に有効です。
ピークの個数を制限します。検出されたピークの個数が設定した個数よりも多かった場合にはY座標が小さいピークから除外されていきます。
ピークの高さが設定したY座標以下のものは除外します。
ピークの高さと個数両方に制限を設けたい場合などで使用します。条件の記述には論理演算子(AND,OR,NOT,LIKE)が使用できます。使用できる変数として"hp"=高さのパーセント,"h"=高さの値,"n"=ピーク番号,"x"=ピークのX値、の4つがあります。
ご不明な点がございましたら、お気軽にお問合せフォームよりテクニカルサポートまでご連絡ください。
その際、必ず「製品名」「バージョン」「シリアル番号」をご連絡ください。
ISO27001(ISMS)認証
情報セキュリティ・マネジメントシステム
© 2026 Lightstone Corp. All Rights Reserved